perf-系统级性能分析工具
系统级性能优化通常包括两个阶段:性能剖析(performance profiling)和代码优化。
性能剖析的目标是寻找性能瓶颈,查找引发性能问题的原因及热点代码。
代码优化的目标是针对具体性能问题而优化代码或编译选项,以改善软件性能。
在性能剖析阶段,需要借助于现有的profiling工具,如perf等。在代码优化阶段往往需要借助开发者的经验,编写简洁高效的代码,甚至在汇编级别合理使用各种指令,合理安排各种指令的执行顺序。
perf是一款Linux性能分析工具。Linux性能计数器是一个新的基于内核的子系统,它提供一个性能分析框架,比如硬件(CPU、PMU(Performance Monitoring Unit))功能和软件(软件计数器、tracepoint)功能。
通过perf,应用程序可以利用PMU、tracepoint和内核中的计数器来进行性能统计。它不但可以分析制定应用程序的性能问题(per thread),也可以用来分析内核的性能问题,当然也可以同时分析应用程序和内核,从而全面理解应用程序中的性能瓶颈。
使用perf,可以分析程序运行期间发生的硬件事件,比如instructions retired、processor clock cycles等;也可以分析软件时间,比如page fault和进程切换。
perf是一款综合性分析工具,大到系统全局性性能,再小到进程线程级别,甚至到函数及汇编级别。
perf提供了十八般武器,可以拿大刀大卸八块,也可以拿起手术刀细致分析。
1. 背景知识
1.1 tracepoints
tracepoints是散落在内核源码中的一些hook,它们可以在特定的代码被执行到时触发,这一特定可以被各种trace/debug工具所使用。
perf将tracepoint产生的时间记录下来,生成报告,通过分析这些报告,便可以了解程序运行期间内核的各种细节,对性能症状做出准确的诊断。
这些tracepint的对应的sysfs节点在/sys/kernel/debug/tracing/events目录下。
1.2 硬件特性之cache
内存读写是很快的,但是还是无法和处理器指令执行速度相比。为了从内存中读取指令和数据,处理器需要等待,用处理器时间来衡量,这种等待非常漫长。cache是一种SRAM,读写速度非常快,能和处理器相匹配。因此将常用的数据保存在cache中,处理器便无需等待,从而提高性能。cache的尺寸一般都很小,充分利用cache是软件调优非常重要部分。
2. 主要关注点
基于性能分析,可以进行算法优化(空间复杂度和时间复杂度权衡)、代码优化(提高执行速度、减少内存占用)。
评估程序对硬件资源的使用情况,例如各级cache的访问次数、各级cache的丢失次数、流水线停顿周期、前端总线访问次数等。
评估程序对操作系统资源的使用情况,系统调用次数、上下文切换次数、任务迁移次数。
事件可以分为三种:
- Hardware Event由PMU部件产生,在特定的条件下探测性能事件是否发生以及发生的次数。比如cache命中。
- Software Event是内核产生的事件,分布在各个功能模块中,统计和操作系统相关性能事件。比如进程切换,tick数等。
- Tracepoint Event是内核中静态tracepoint所触发的事件,这些tracepoint用来判断程序运行期间内核的行为细节,比如slab分配器的分配次数等。
3. perf的使用
perf –help后可以看到perf的二级命令
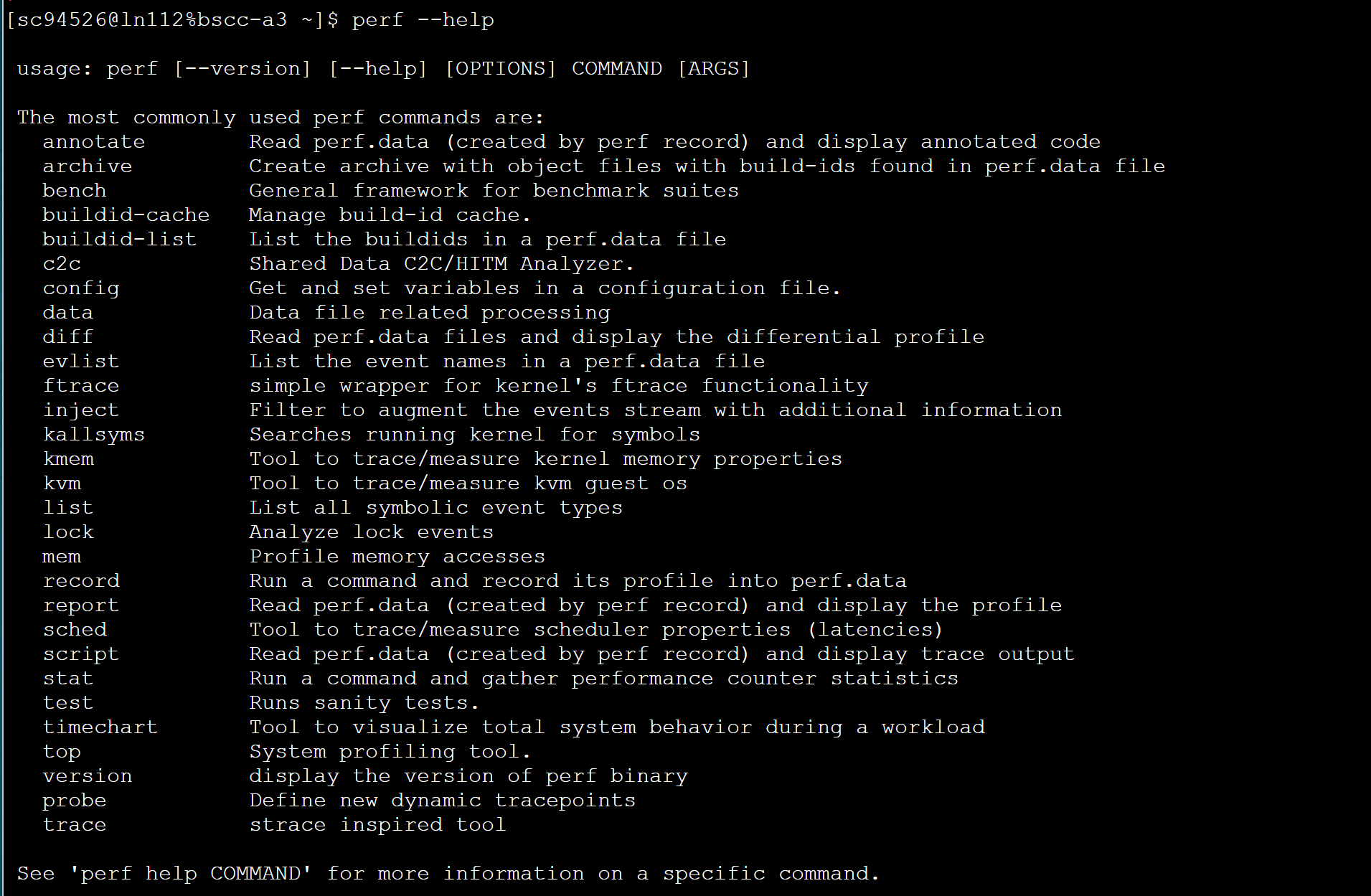
3.1perf list
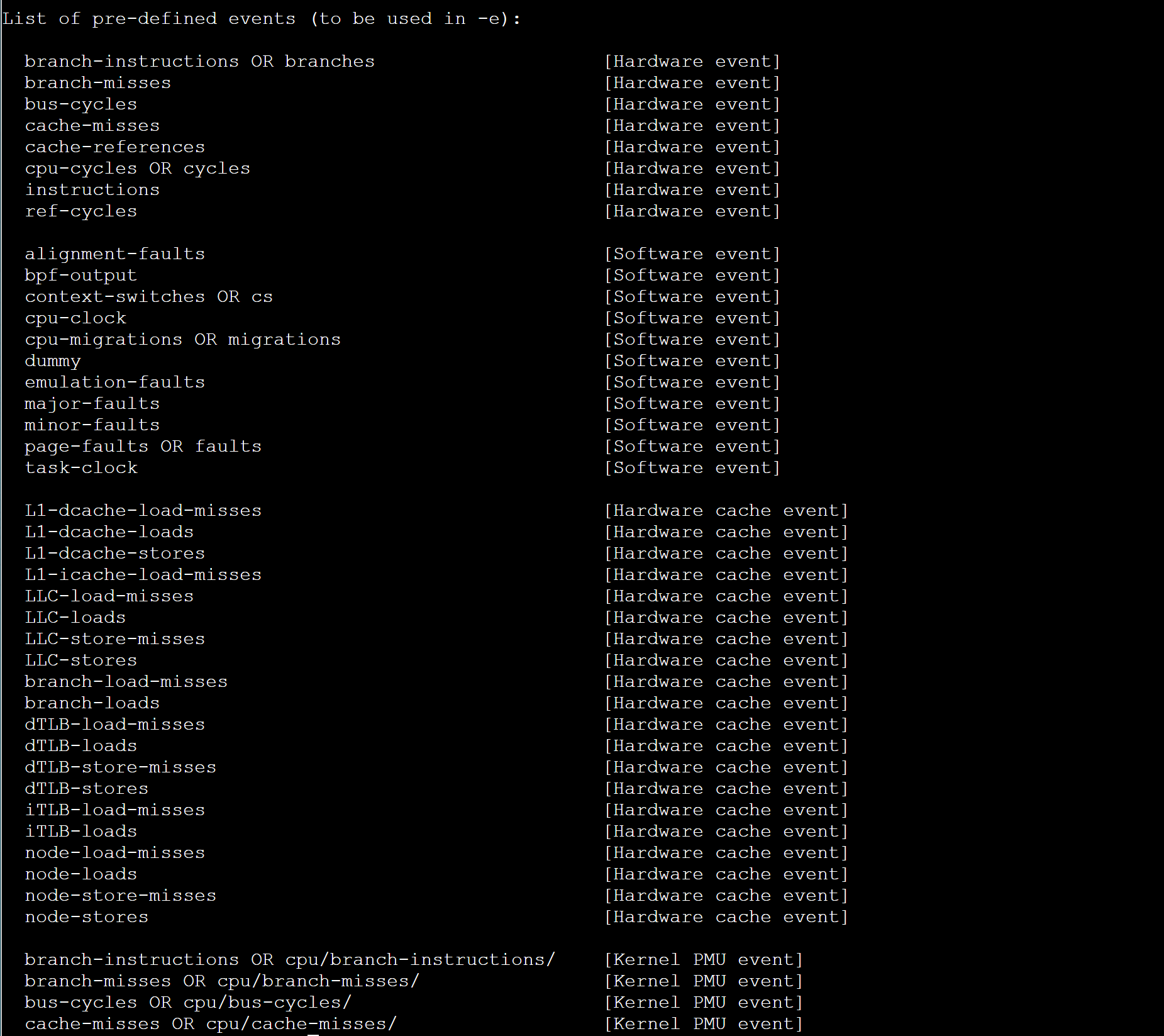
perf list查看支持的事件类型
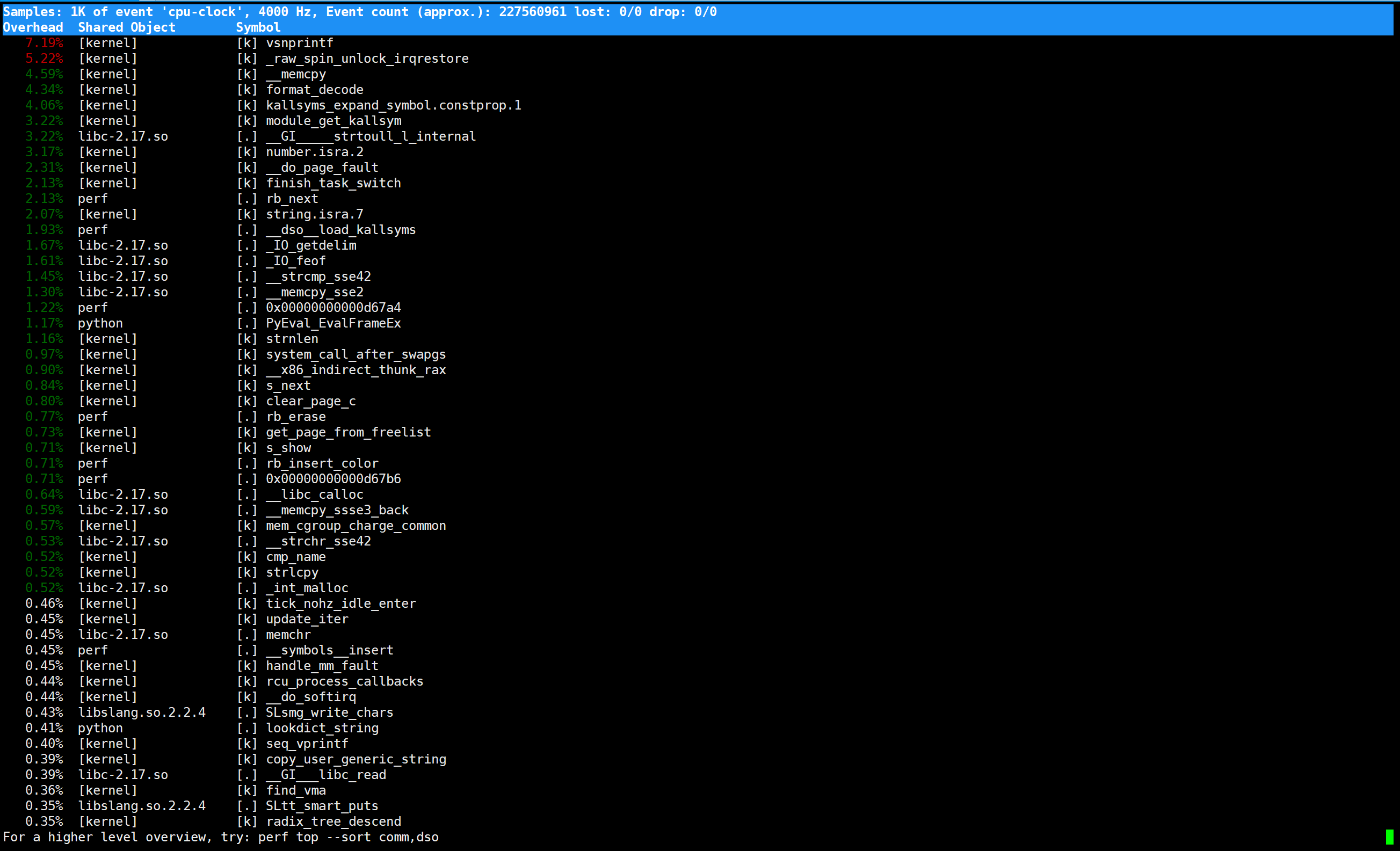
3.2perf top
即可以正常显示perf top如下:
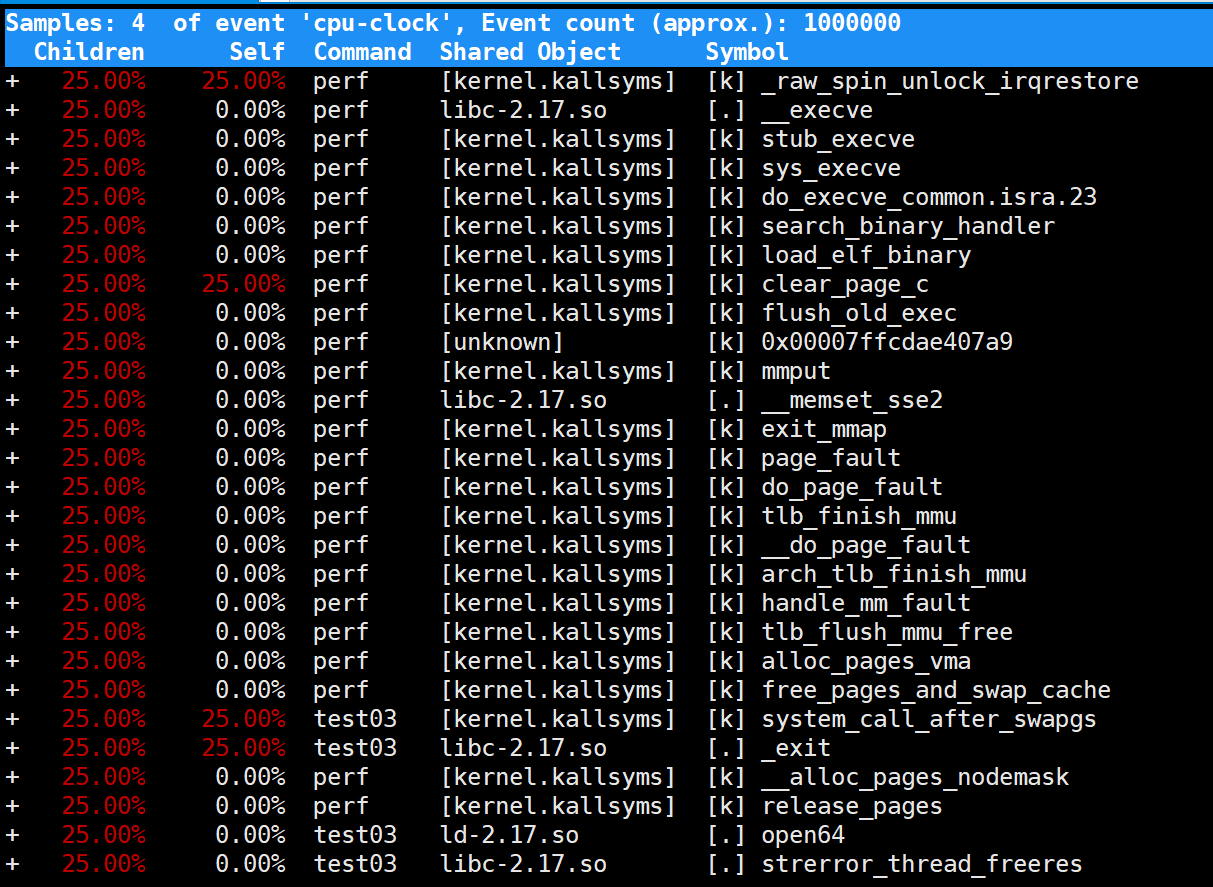
第一列:符号引发的性能事件的比例,指占用的cpu周期比例。
第二列:符号所在的DSO(Dynamic Shared Object),可以是应用程序、内核、动态链接库、模块。
第三列:DSO的类型。[.]表示此符号属于用户态的ELF文件,包括可执行文件与动态链接库;[k]表述此符号属于内核或模块。
第四列:符号名。有些符号不能解析为函数名,只能用地址表示。
3.3 perf stat
perf stat用于运行指令,并分析其统计结果。虽然perf top也可以指定pid,但是必须先启动应用才能查看信息。
perf stat能完整统计应用整个生命周期的信息。
命令格式为:
perf stat [-e
| –event=EVENT] [-a]
perf stat [-e| –event=EVENT] [-a] — [ ]
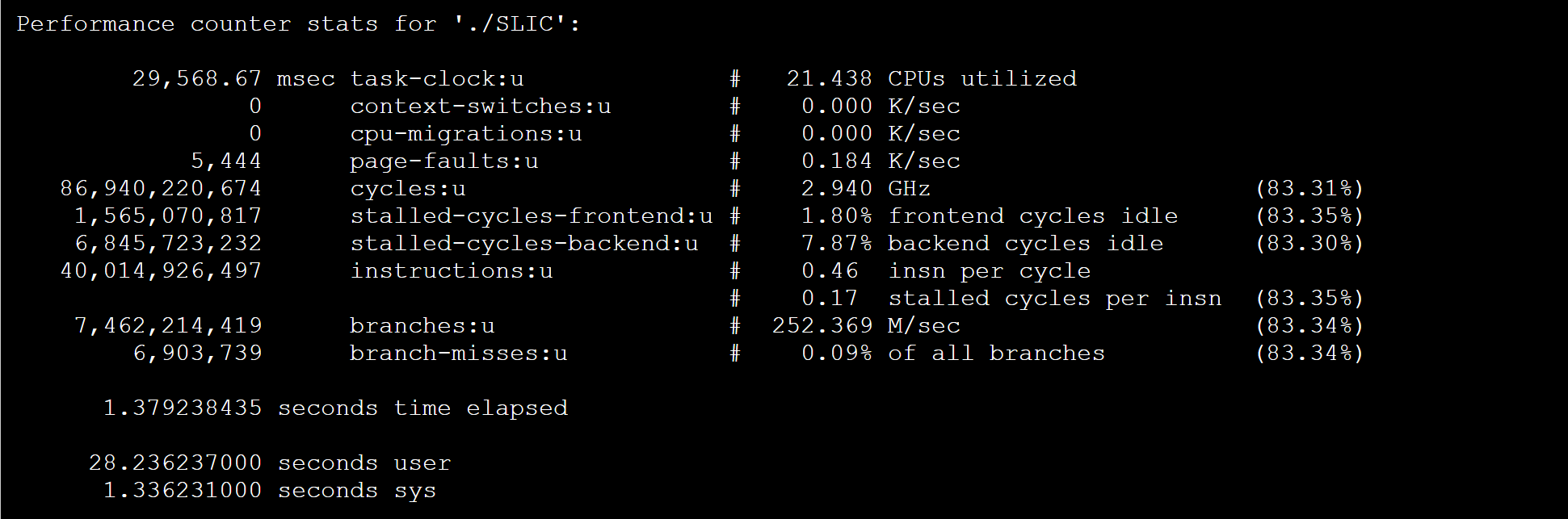
cpu-clock:任务真正占用的处理器时间,单位为ms。CPUs utilized = task-clock / time elapsed,CPU的占用率。
context-switches:程序在运行过程中上下文的切换次数。
CPU-migrations:程序在运行过程中发生的处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU迁移到另一个CPU。
CPU迁移和上下文切换:发生上下文切换不一定会发生CPU迁移,而发生CPU迁移时肯定会发生上下文切换。发生上下文切换有可能只是把上下文从当前CPU中换出,下一次调度器还是将进程安排在这个CPU上执行。
page-faults:缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常。另外TLB不命中,页面访问权限不匹配等情况也会触发缺页异常。
cycles:消耗的处理器周期数。如果把被ls使用的cpu cycles看成是一个处理器的,那么它的主频为2.486GHz。可以用cycles / task-clock算出。
stalled-cycles-frontend:指令读取或解码的质量步骤,未能按理想状态发挥并行左右,发生停滞的时钟周期。
stalled-cycles-backend:指令执行步骤,发生停滞的时钟周期。
instructions:执行了多少条指令。IPC为平均每个cpu cycle执行了多少条指令。
branches:遇到的分支指令数。branch-misses是预测错误的分支指令数。
3.4 perf record & report
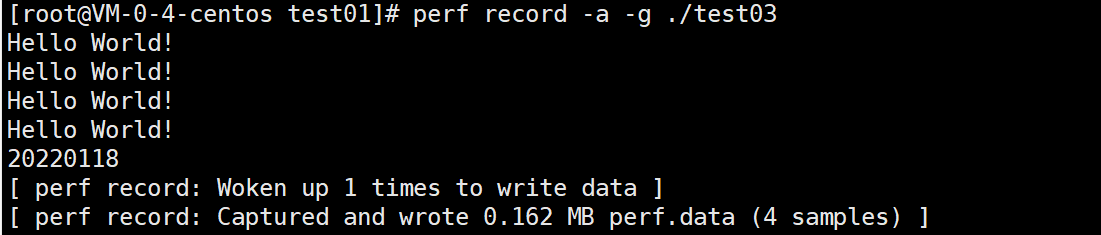
运行一个命令,并将其数据保存到perf.data中。随后,可以使用perf report进行分析。
perf record和perf report可以更精确的分析一个应用,perf record可以精确到函数级别。并且在函数里面混合显示汇编语言和代码。

1.编译程序(这里以test.c为例子)

2.perf record
3.perf report

参考资料
系统级性能分析工具perf的介绍与使用 - ArnoldLu - 博客园 (cnblogs.com)-系统性能分析工具perf的介绍与使用
如何使用gcov和perf工具抓热点代码 - 陈小欧 - 20210331 - PLCT实验室_哔哩哔哩_bilibili-如何使用gcov和perf工具抓热点代码 - 陈小欧 - 20210331 - PLCT实验室
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!