OpenMP循环调度
OpenMP循环调度
1.循环调度
当第一次遇到parallel for指令时,我们看到将各次循环分配给线程的操作是由系统完成的。然而,大部分OpenMP实现只是粗略地使用块分割:如果在串行循环中有n次迭代,那么在并行循环中,前n/thread_count个迭代分配给线程0,接下来的n/thread_count个迭代分配给线程1,依此类推。不难想到,这种分配方式肯定不是最优的。例如,假如我们想要并行化循环:
1 | |
同时,假设对f函数调用所需要的时间与参数i的大小成正比,那么与分配给线程0的工作相比,分配给线程thread_count-1的工作量相对较大。一个更好的分配方案是轮流分配线程的工作(循环划分)。在循环划分中,各次迭代被“轮流”地一次一个地分配给线程。假如 t=thread_count。那么一个循环划分将如下分配各次迭代:

为了了解这样分配是如何影响性能的,我们编写了如下程序。
1 | |
每当函数f(i)调用i次sin函数。例如,执行f(2i)的时间几乎是执行f(i)的时间的两倍。
当n=10000并且只用一个线程运行程序时,运行时间是3.67秒。当用两个线程和缺省分配方式(第0-5000次迭代分配给线程0,第5001-10000次迭代分配给线程1),运行程序时,运行时间为2.76秒。加速比仅为1.33.然而,当运行两个线程并采用循环划分时,运行时间减少到1.84秒。与单线程运行相比,加速比为1.99;与双线程,块分割相比,加速比为1.5!
我们看到一个好的迭代分配能够对性能有很大的影响。再OpenMP中,将循环分配给线程称为调度,schedule子句用于在parallel for或者for指令中进行迭代分配。
2.schedule子句
在例子中,我们已经知道如何乎获取缺省调度:只需要添加parallel for指令和reduction子句:
1 | |
为了对线程进行调度,可以添加一个schedule子句到parallel for指令中:
1 | |
一般而言,schedule子句有如下形式:
schedule(
type可以是下列任意一个:
- static:迭代能够在循环执行前分配给线程
- dynamic或guided:迭代在循环执行时被分配给线程,因此在一个线程完成了它的当前迭代集合后,它能从运行时系统中请求更多
- auto:编译器和运行时系统决定调度方式
- runtime:调度在运行时决定
chunksize是一个正整数。在OpenMP中,迭代块是在顺序循环中连续执行的一块迭代语句,块中的迭代次数是chunksize。只有static,dynamic和guided调度有chunksize。这虽然决定了调度的细节,但准确的解释还是依赖于type。
3.stastic调度类型
对于static调度,系统以轮转的方式分配chunksize块个迭代给每个线程。例如,假如有12个迭代,0,1,—,11和3个线程,如果在parallel for或for指令中使用schedule(static,1)迭代将如下分配:

如果使用schedule(static,2),迭代将如下进行分配:

如果使用schedule(static,4),迭代将如下分配:

因此,子句schedule(static,total_iterations/thread_count)就相当于被大部分OpenMP实现所使用的缺省调度。
这里,chunksize可以被忽略。如果他被忽略了,chunksize就近似等于total_iterations/thread_count。
4.dynamic和guided调度类型
在dynamic调度中,迭代也被分成chunksize个连续迭代的块。每个线程执行一块,并且当一个线程完成一块时,它将从运行时系统请求另一块,直到所有的迭代完成。chunksize可以被忽略。当它被忽略时,chunksize为1。
在guided调度中,每个线程也执行一块,并且当一个线程完成一块时,将请求另一块。然而,在guided调度中,当块完成后,新块的大小会变小。例如,在我们的系统中,如果用parallel for指令和schedule(guided)子句来运行梯形积分法程序,那么当n=10000并且thread_count=2时。迭代将如表5-3那样分配。块的大小近似等于剩下的迭代数除以线程数。第一个块的大小9999/2≈5000,因为有9999个迭代未被分配的迭代。第二个块的大小为4999/2≈2500,一次类推。
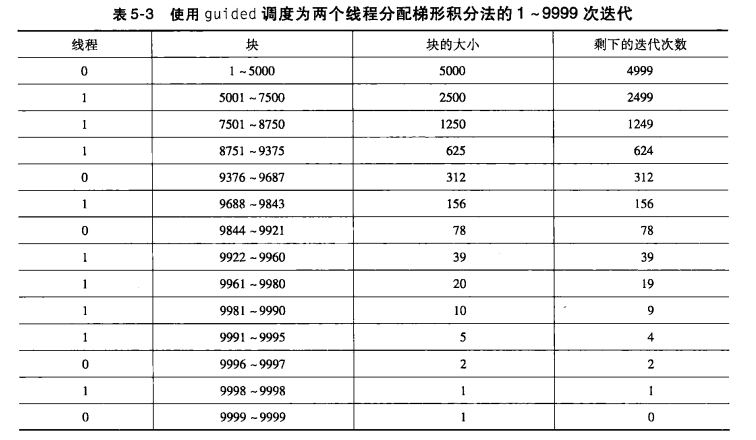
在guided调度中,如果没有指定chunksize,那么块的大小为1;如果指定了chunksize,那么块的大小就是chunksize,除了最后一块的大小可以比chunksize小。
5.runtime调度类型
为了理解schedule(runtime),我们需要离题一会儿,讨论一下环境变量。正如名字所暗示的,环境变量是能够被运行时系统所访问的命名值,即它们在程序的环境中是可得的。一些经常被使用的环境变量是PATH,HOME和SHELL。PATH变量明确了当寻找一个可执行文件时shell应该搜索哪些目录。它通常在UNIX和Windows系统中定义。HOME变量指定用户主目录的位置,而SHELL变量指定用户shell的可执行位置。这样通常在UNIX系统中。在类UNIX系统(例如Linux和Mac OS X)和Windows,环境变量能够在命令行中检查和指定。在类UNIX系统中,能使用shell命令行;在windows中,能使用集成开发环境的命令行。
例如,如果我们正使用bash shell,要检查一个环境变量的值只需要输入
1 | |
我们能够使用export命令来设置一个环境变量的值
1 | |
如何检查和设置特定系统的环境变量,请咨询本地系统的专家。
当schedule(runtime)指定时,系统使用环境变量OMP_SCHEDULE在运行时来决定如何调度循环。OMP_SCHEDULE环境变量会呈现任何能够被static,dynamic或guided调度所使用的值。例如,假设在程序中有一条parallel for指令,并且它已经被schedule(runtime)修改了。那么如果使用bash shell,就能通过执行以下命令将一个循环分配所得到的迭代分配给线程:
1 | |
现在,当开始执行程序时,系统将调度for循环的迭代,就如同使用子句schedule(static,1)修改了parallel for指令那样。
6.调度选择
如果需要并行化一个for循环,那么我们如何决定使用哪一种电镀和chuncksize的大小?实际上,每一中schedule子句有不同的系统开销。dynamic调度的系统开销要大于static调度,而guided调度的系统开销是三种方式中最大的。因此,如果不使用schedule子句就已经达到了令人满意的性能,就不需要进行多余的工作。但是,如果我们怀疑调度的性能可以提升,那么我们可以对各种调度进行试验。
在本节开始提供的例子中,在程序使用两个线程的情况下,使用schedule(static,1)代替默认调度时,加速比从1.33提升到1.99。因为在两个线程的条件下,加速比几乎不可能比1.99更好,所以我们可以不用再尝试其他的调度方式,至少在只用两个线程并且迭代数为10000的情况下是这样。如果做更多的试验,改变线程的个数和迭代的次数,我们可能会发现:最优的调度方式是由线程的个数和迭代的次数共同决定的。
如果我们断定默认的调度方式性能低下,那么我们会做大量的实验来寻找最优的调度方式和迭代次数。在进行了大量的工作以后,我们可能发现,这些循环没有得到很好的并行化,没有哪一种调度可以带来比较显著的性能提升。编程作业5.4就是这样一个例子。
但在某些情况下,应该优先考虑有些调度:
- 如果循环的每次迭代需要几乎相同的计算量,那么可能默认的调度方式能提供最好的性能
- 如果随着循环的进行,迭代的计算量线性猛增(或递减),那么采用比较小的chuncksize的static调度可能会提供最好的性能
- 如果每次迭代的开销事先不能确定,那么就可能需要尝试使用多种不同的调度策略。在这种情况下,应当使用schedule(runtime)子句,通过富裕环境变量OMP_SCHEDULE不同的值来比较不同调度策略下程序的性能
7.总结
- 调度方式对加速效果的重要性
- 合理分析任务特性,选择最适合的调度方式
8.参考资料
并行程序导论 (美)Peter S.Pacheco
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!