CUDA编程结构
CUDA编程结构
CUDA编程模型使用由C语言扩展生成的注释代码在异构计算系统中执行应用程序。
在一个异构环境中包含多个CPU和GPU,每个GPU和CPU的内存都由一条PCI-Express总线分隔开。因此,需要注意区别以下内容。
- 主机:CPU及其内存(主机内存)
- 设备:GPU及其内存(设备内存)
为了清楚地指明不同的内存空间,在本书的示例代码中,主机内存中的变量名以h__为前缀,设备内存中的变量名以d__为前缀。
从CUDA6.0开始,NVDIA提出了名为“统一寻址”(Unified Memory)的编程模型的改进,它连接了主机内存和设备内存空间,可使用单个指针访问CPU和GPU内存,无须彼此之间手动拷贝数据。现在,重要的是应学会如何为主机和设备分配内存空间以及如何在CPU和GPU之间拷贝共享数据。这种程序员管理模式控制下的内存和数据可以优化应用程序并实现硬件系统利用率的最大化。
内核(kernel)是CUDA编程模型的一个重要组成部分,其代码在GPU上运行。作为一个开发人员,你可以串行的执行核函数。在此背景下,CUDA的调度管理程序员在GPU线程上编写核函数。在主机上,基于应用程序数据以及GPU的性能定义如何让设备实现算法功能。这样做的目的是使你专注于算法的逻辑(通过编写串行代码),且在创建和管理大量的GPU线程时不必拘泥于细节。
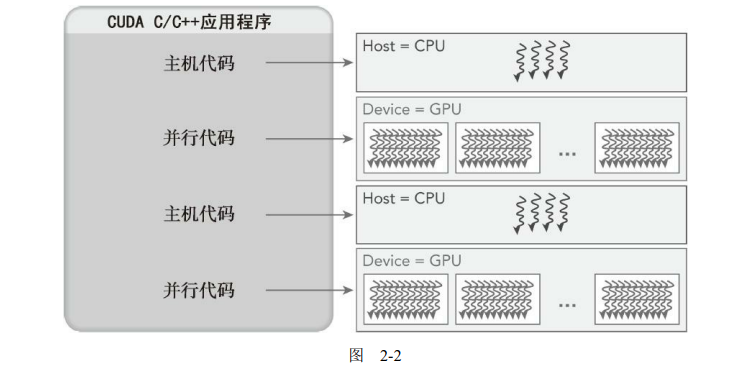
多数情况下,主机可以独立地对设备进行操作。内核一旦被启动,端粒权立刻返回给主机,释放CPU来执行由设备上运行的并行代码实现的额外的任务。CUDA编程模型主要是异步的,因此在GPU上进行的运算可以与主机-设备通信重叠。一个典型的CUDA程序包括由并行代码互补的串行代码。如图2-2所示,串行代码(及任务并行代码)在主机CPU上执行,而并行代码在GPU上执行。主机代码按照ANSI C标准进行编写,而设备代码使用CUDA C进行编写。你可以将所有的代码统一放在一个源文件中,也可以使用多个源文件来构建应用程序和库。NVIDIA的C编译器(nvcc)为主机和设备生成可执行代码。
一个典型的CUDA程序实现流程遵循以下模式
- 把数据从CPU内存拷贝到GPU内存
- 调用核函数对存储在GPU内存中的数据进行操作
- 将数据从GPU内存传送回到CPU内存
首先,你要学习的是内存管理及主机和设备之间的数据传输。
参考资料
CUDA C编程权威指南 程润伟,Max Grossman(美),Ty Mckercher
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!