启动一个CUDA核函数
启动一个CUDA核函数
你应该对下列C语言函数调用语句很熟悉:
1 | |
CUDA内核调用是对C语言函数调用语句的延申,<<<>>>运算符内是核函数的执行配置。
1 | |
正如上一节所述,CUDA编程模型揭示了线程层次结构。利用执行配置可以指定线程在GPU上调度运行的方式。执行配置的第一个值是网格维度,也就是启动块的数目。第二个值是块维度,也就是每个块中线程的数目。通过指定网格和块的维度,你可以进行一下配置:
- 内核中线程的数目
- 内核中使用的线程布局
同一个块中的线程之间可以相互协作,不同块内的线程不能协作。对于一个给定的问题,可以使用不同的网格和块布局来组织你的线程。例如,假设你有32个数据元素用于计算,每8个元素一个块,需要启动4个块:
1 | |
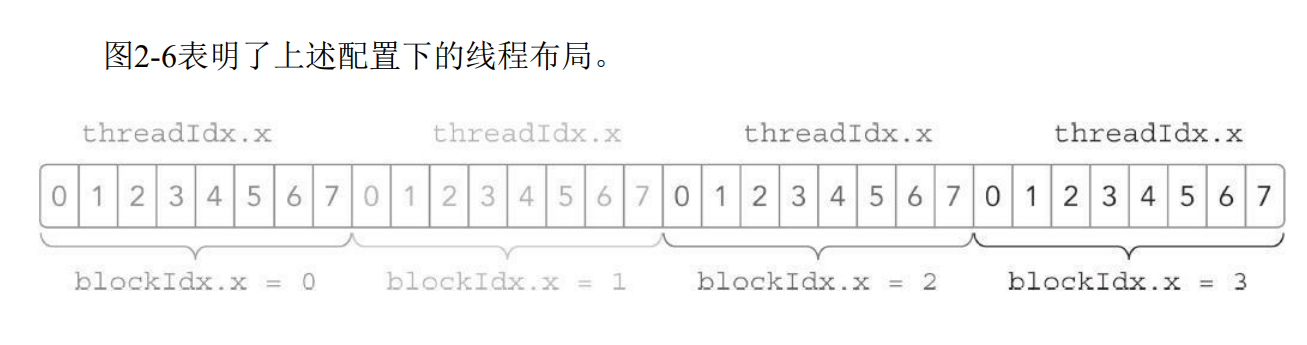
由于数据在全局内存中是线性存储的,因此可以用变量blockIdx.x和threadIdx.x来进行以下操作。
- 在网格中标识一个唯一的线程
- 建立线程和数据元素之间的映射关系
如果把32个元素放到一个块里,那么只会得到一个块:
1 | |
如果每个块只含一个元素,那么会有32个块:
1 | |
核函数的调用与主机线程是异步的。核函数调用结束后,控制权立刻返回给主机端。你可以调用以下函数来强制主机端程序等待所有的核函数执行结束:
1 | |
一些CUDA运行时API在主机和设备之间是隐式同步的。当使用cudaMemcpy函数在主机和设备之间拷贝数据时,主机端隐式同步,即主机端程序必须等待数据拷贝完成后才能继续执行程序。
1 | |
之前所有的核函数调用完成后开始拷贝数据。当拷贝完成后,控制权立刻返回给主机端。
异步行为
不同于C语言的函数调用,所有的CUDA核函数的启动都是异步的。CUDA内核调用完成后,控制权立刻返回给CPU。
参考资料
CUDA C编程权威指南 程润伟,Max Grossman(美),Ty Mckercher
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!