CUDA编写核函数
编写核函数
核函数是在设备端执行的代码。在核函数中,需要为一个线程规定要进行的计算以及要进行的数据访问。当核函数被调用时,许多不同的CUDA线程并行执行同一个计算任务。以下是用_global_
声明定义核函数:
1 | |
核函数必须有一个void返回类型。
表2-2总结了CUDA C程序中的函数类型限定符。函数类型限定符指定一个函数在主机上执行还是在设备上执行,以及可被主机调用还是被设备调用。
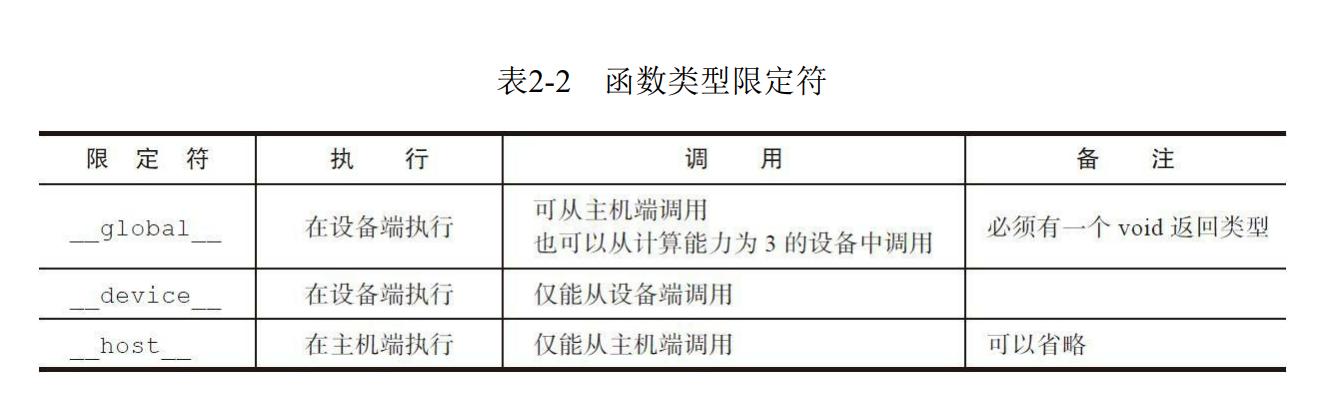
_device_ 和 __host__限定符可以一齐使用,这样函数可以同时在主机和设备端进行编译。
CUDA核函数的限制
以下限制适用于所有核函数:
- 只能访问设备内存
- 必须具有void返回类型
- 不支持可变数量的参数
- 不支持静态变量
- 显示异步行为
考虑一个简单的例子:将两个大小为N的向量A和B相加,主机端的向量加法C代码如下:
1 | |
这是一个迭代N次的串行程序,循环结束后将产生以下核函数:
1 | |
C函数和核函数之间有什么不同?你可能已经注意到循环体消失了,内置的线程坐标变量替换了数组索引,由于N是被隐式定义用来启动N个线程的,所以N没有什么参考价值。
假设有一个长度为32个元素的向量,你可以按以下方法用32个线程来调用核函数:
1 | |
参考资料
CUDA C编程权威指南 程润伟,Max Grossman(美),Ty Mckercher
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!