CUDA给核函数计时
在内核的性能转换过程中,了解核函数的执行需要多长时间是很有帮助并且十分关键的。衡量核函数性能的方法有很多。最简单的方法是在主机端使用一个CPU或GPU计时器来计算内核的执行时间。在本节,你需要设置一个CPU计时器,并使用NVIDIA分析工具来计算执行时间。
用CPU计时器计时
可以使用gettimeofday系统调用来创建一个CPU计时器,以获取系统的时钟时间,它将返回自1970年1月1日零点以来,到现在的秒数。程序中需要添加sys/time.h头文件,如代码清单2-5所示。
| double cpuSecond()
{
struct timeval tp;
gettimeofday(&tp,NULL);
return ((double)tp.tv_sec + (double)tp.tv_usec*1.e-6);
}
|
你可以用cpuSecond函数来测试你的核函数:
| double iStart = cpuSecond();
kernel_name<<<grid,block>>>(argument list);
cudaDeviceSynchronize();
double iElaps = cpuSecond() - iStart;
|
由于核函数调用与主机端程序是异步的,你需要用cudaDeviceSynchronize函数来等待所有的GPU线程运行结束。变量iElaps表示程序运行的时间,就像你用手表记录的核函数的执行时间(用秒计算)。
现在,通过设置数据集大小来对一个有16M个元素的大向量进行测试:
由于GPU的可扩展性,你需要借助块和线程的索引来计算一个按行优先的数组索引 i ,并对核函数进行修改,添加限定条件(i < N)来检验索引值是否越界,如下所示:
| __global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N){
int i = blockIdx.x * blockDim.x + threadIdx.x;
if( n < N) C[i] = A[i] + B[i];
}
|
有了这些更改,可以使用不同的执行配置来衡量核函数。为了解决创建的线程总数大于向量元素总数的情况,你需要限制内核不能非法访问全局内存,如图2-7所示。

代码清单2-5展示了如何在主函数中用CPU计时器测试向量加法的核函数。
代码清单2-5 测试向量加法的核函数(sumArraysOnGPU-timer.cu)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| #include <cuda_runtime.h>
#include <stdio.h>
#include <sys/time.h>
int main(int argc,char **argv){
printf("%s Starting...\n",argv[0]);
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
int nElem = 1<<24;
printf("Vector size %d\n",nElem);
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float*)malloc(nBytes);
h_B = (float*)malloc(nBytes);
hostRef = (float*)malloc(nBytes);
gpuRef = (float*)malloc(nBytes);
double iStart,iElaps;
iStart = cpuSecond();
initialData(h_A, nElem);
initialData(h_B, nElem);
iElaps = cpuSecond() - iStart;
memset(hostRef, 0 ,nBytes);
memset(gpuRef, 0 ,nBytes);
iStart = cpuSecond();
sumArraysOnHost(h_A, h_B, hostRef, nElem);
iElaps = cpuSecond() - iStart;
float *d_A, *d_B, *d_C;
cudaMalloc((float**)&d_A, nBytes);
cudaMalloc((float**)&d_B, nBytes);
cudaMalloc((float**)&d_C, nBytes);
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostTodevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostTodevice);
int iLen = 1024;
dim3 block(iLen);
dim3 grid((nElem+block.x-1))/block.x);
iStart = cpuSecond();
sumArraysOnGPU<<<grid,block>>>(d_A, d_B, d_C,nElem);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
printf("sumArraysOnGPU<<<%d,%d>>> Time elapsed %f sec\n",grid.x, block.x, iElaps);
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
checkResult(hostRef, gpuRef, nElem);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return(0);
}
|
默认的执行配置被设置为一个包含16384个块的一维网格,每个块包含1024个线程。用以下命令编译并运行程序:
| nvcc sumArraysOnGPU-timer.cu -o sumArraysOnGPU-timer
./sumArraysOnGPU-timer
|
在基于英特尔Sandy Bridge架构的系统上进行测试,从代码清单2-5的示例中可以看出,在GPU上进行的向量加法的运算速度是在CPU上运行向量加法的3.86倍。
| ./sumArraysOnGPU-timer Starting...
Using Device 0:Tesia M2070
Vector size 16777216
sumArraysOnGPU<<<16384, 1024>>> Time elapsed 0.002456 sec
Arrays match.
|
把块的维度减少到512可以创建32768个块。在这个新的配置下,内核的性能提升了1.19倍。
| sumArraysOnGPU<<<32768, 512>>> Time elapsed 0.002058 sec
|
如果进一步将块的维度降低到256,系统将提示以下错误信息,信息表示块的总数超过一维网格的限制。
| ./sumArraysOnGPU-timer Starting...
Using Device 0: Tesla M2070
Vector size 16777216
sumArraysOnGPU<<<65536, 256>>> Time elapsed 0.000183 sec
Error: sumArraysOnGPU-timer.cu:153, code:9, reason: invalid configuration argument
|
了解自身局限性
在调整执行配置时需要了解的一个关键点是对网格和块维度的限制。线程层次结构中每个层次的最大尺寸取决于设备。
CUDA提供了通过查询GPU来了解这些限制的能力。
对于Fermi设备,每个块的最大线程数是1024,且网格的x,y,z三个方向上的维度最大值是65535
用nvprof工具计时
自CUDA 5.0以来,NVIDIA提供了一个名为nvprof的命令行分析工具,可以帮助从应用程序的CPU和GPU活动情况中获取时间线信息,其包括内核执行,内存传输以及CUDA API的调用。其用法如下。
| nvprof [nvprof_args] <application> [application_args]
|
可以使用以下命令获取更多关于nvprof的帮助信息:
你可以用如下命令去测试内核:
| nvprof ./sumArraysOnGPU-timer
|
nvprof的输出结果会因为你使用的GPU类型不同而有所差异。以下结果是从Tesla GPU中得到的:
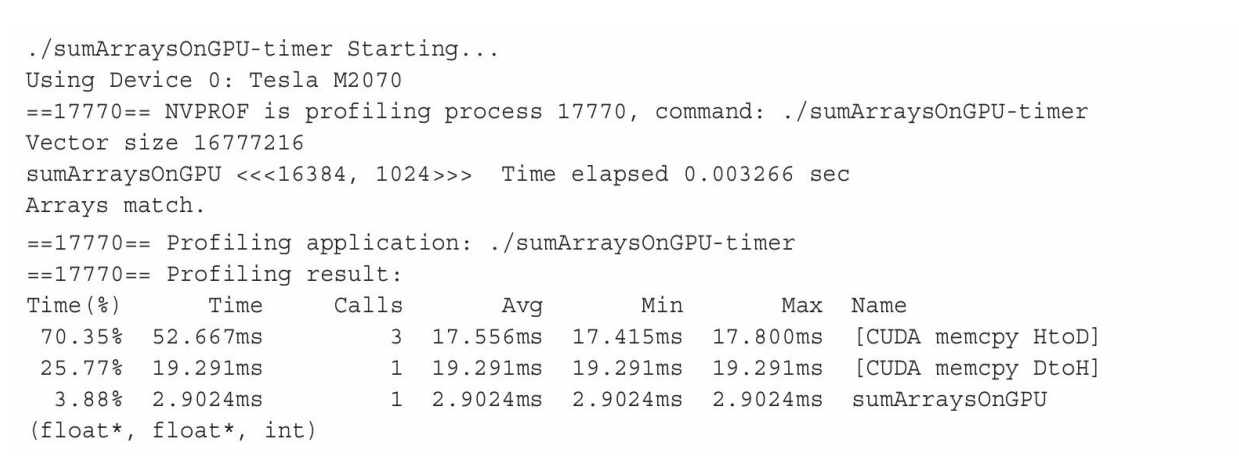
以上结果的前半部分来自于程序的输出,后半部分来自于nvprof的输出。可以注意到,CPU计时器显示消耗的内核时间为3.26ms,而nvprof显示消耗的内核时间为2.90ms。在这个例子中,nvprof的结果更为精确,因为CPU计时器测量的时间中包含了来自nvprof附加的时间。
nvprof是一个能帮助你理解在执行应用程序时所花费的时间主要用在何处的强大工具。可以注意到,在这个例子中,主机和设备之间的数据传输需要的时间比内核执行的时间要多。图2-8所描绘的时间线(未按比例绘制),显示了在CPU上消耗的时间,数据传输所用的时间以及在GPU上计算所用的时间。
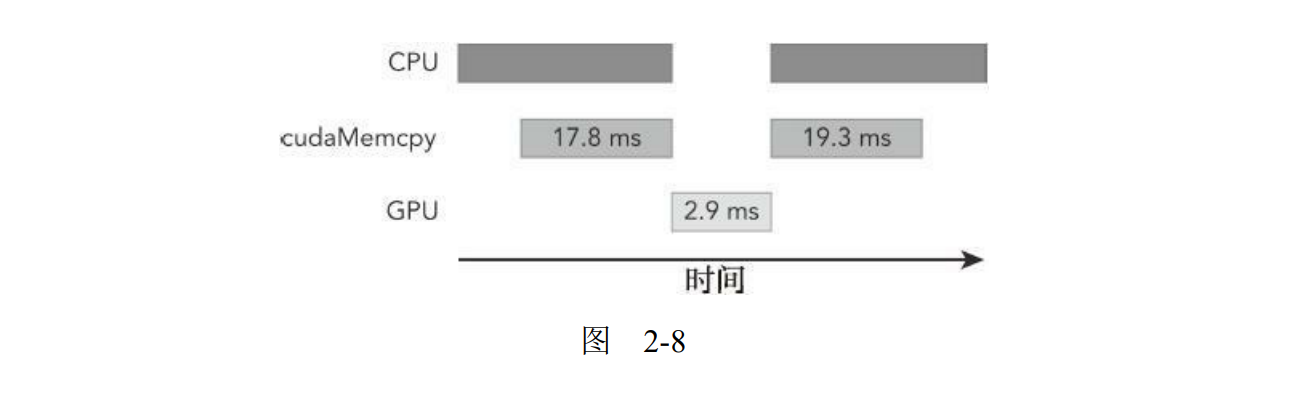
对于HPC工作负载,理解程序中通信比的计算是非常重要的。如果你的应用程序用于计算的时间大于数据传输所用的时间,那么或许可以压缩这些操作,并完全隐藏与传输数据有关的延迟。如果你的应用程序用于计算的时间少于数据传输所用的时间,那么需要尽量减少主机和设备之间的传输。
比较应用程序的性能将理论界限最大化
在进行程序优化时,如何将应用程序和理论界限进行比较是很重要的。由nvprof得到的计数器可以帮助你获取应用程序的指令和内存吞吐量。如果将应用程序的测量值与理论峰值进行比较,可以判定你的应用程序的性能是受限于算法还是受限于内存带宽的。以Tesla K10为例,可以得到理论上的比率:
Tesla K10单精度峰值浮点运算次数
745 MHz核心频率*2 GPU/芯片* (8个多处理器192个浮点单元32核心/多处理器)*2OPS/周期 = 4.58 TFLOPS (FLOPS表示每秒浮点运算次数)
Tesla K10内存带宽峰值
2 GPU/芯片256位2500 MHz内存时钟*2 DDR/8位/字节 = 320 GB/s
指令比:字节
4.58 TFLOPS/320 GB/s, 也就是13.6个指令:1个字节
对于Tesla K10而言,如果你的应用程序每访问一个字节所产生的指令数多于13.6,那么你的应用程序受算法性能限制。大多数HPC工作负载受内存带宽的限制。
参考资料
CUDA C编程权威指南 程润伟,Max Grossman(美),Ty Mckercher