CUDA使用块和线程建立矩阵索引
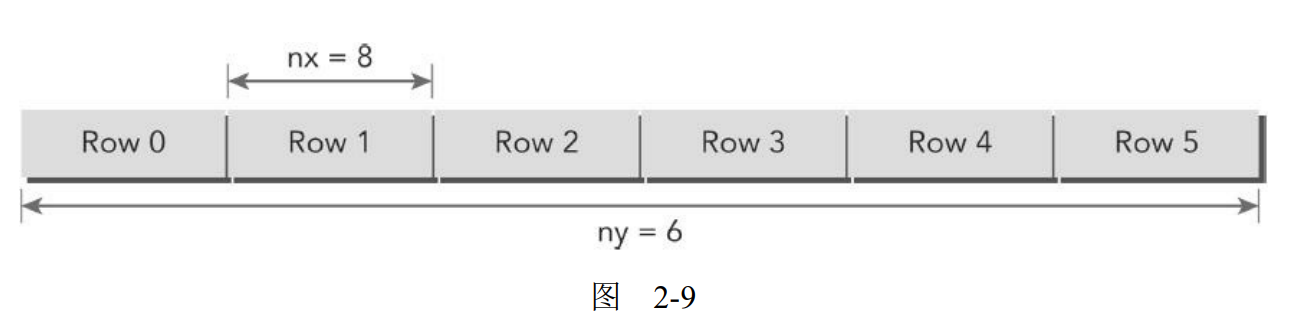
通常情况下,一个矩阵用行优先的方法在全局内存中进行线性存储。图2-9所示的是一个8×6矩阵的小例子。
在一个矩阵加法核函数中,一个线程通常被分配一个数据元素来处理。首先要完成的任务是使用块和线程索引从全局内存中访问指定的数据。通常情况下,对一个二维示例来说,需要管理3种索引。
- 线程和块索引
- 矩阵中给定点的坐标
- 全局线性内存中的偏移量
对于一个给定的线程,首先可以通过把线程和块索引映射到矩阵坐标上来获取线程块和线程索引的全局内存偏移量,然后将这些矩阵坐标映射到全局内存的存储单元中。
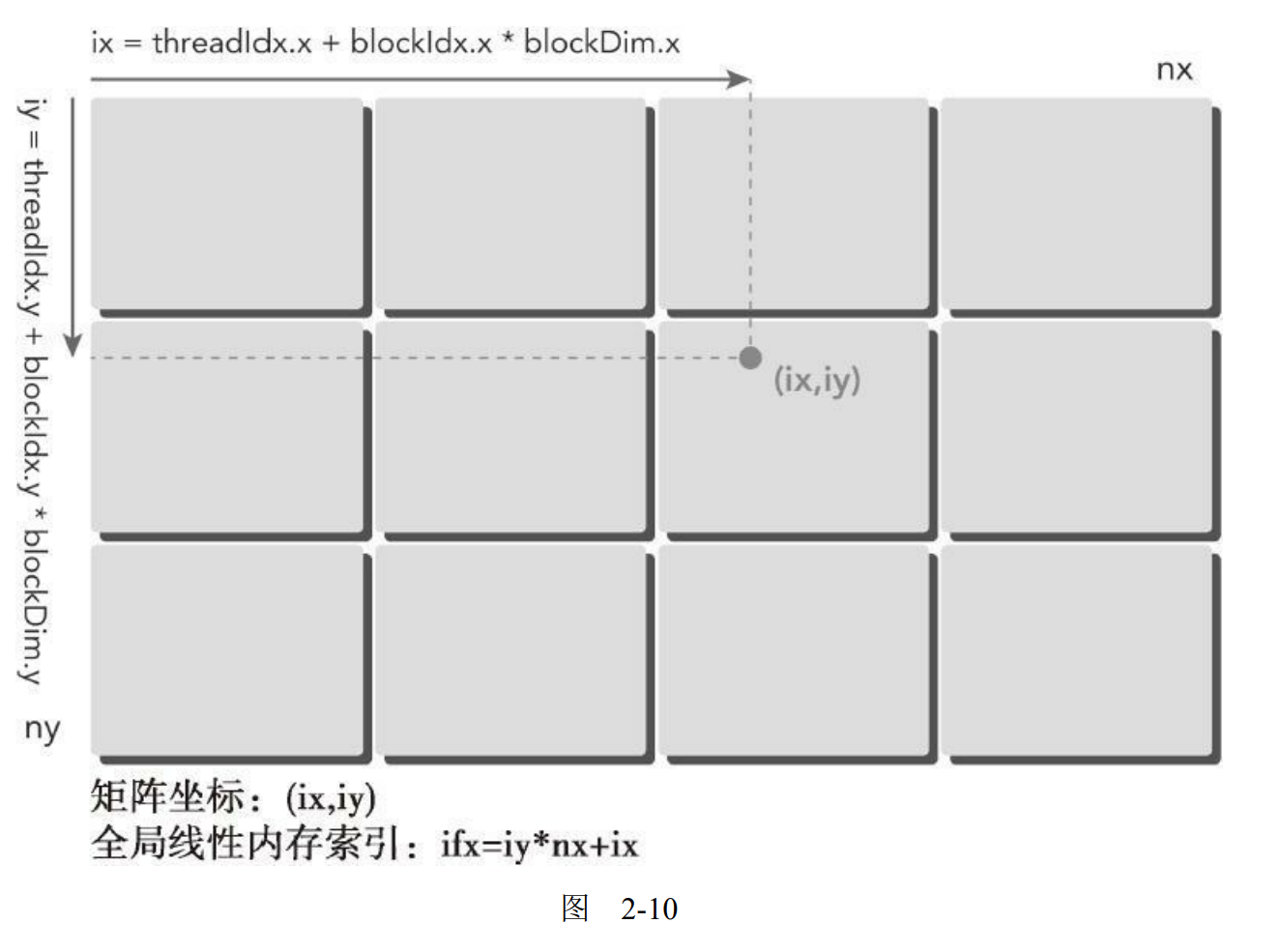
第一步,可以用以下公式把线程和块索引映射到矩阵坐标上:
| ix = threadIdx.x + blockIdx.x * blockDim.x;
iy = threadIdx.y + blockIdx.y * blockDim.y;
|
第二步,可以用以下公式把矩阵坐标映射到全局内存中的索引/存储单元上:
图2-10说明了块和线程索引,矩阵坐标以及线性全局内存索引之间的对应关系。
printThreadInfo函数被用于输出关于每个线程的以下信息:
- 线程索引
- 块索引
- 矩阵坐标
- 线性全局内存偏移量
- 相应元素的值
用以下命令编译并运行该程序:
| nvcc -arch=sm_20 checkThreadIndex.cu -o checkIndex
./checkIndex
|
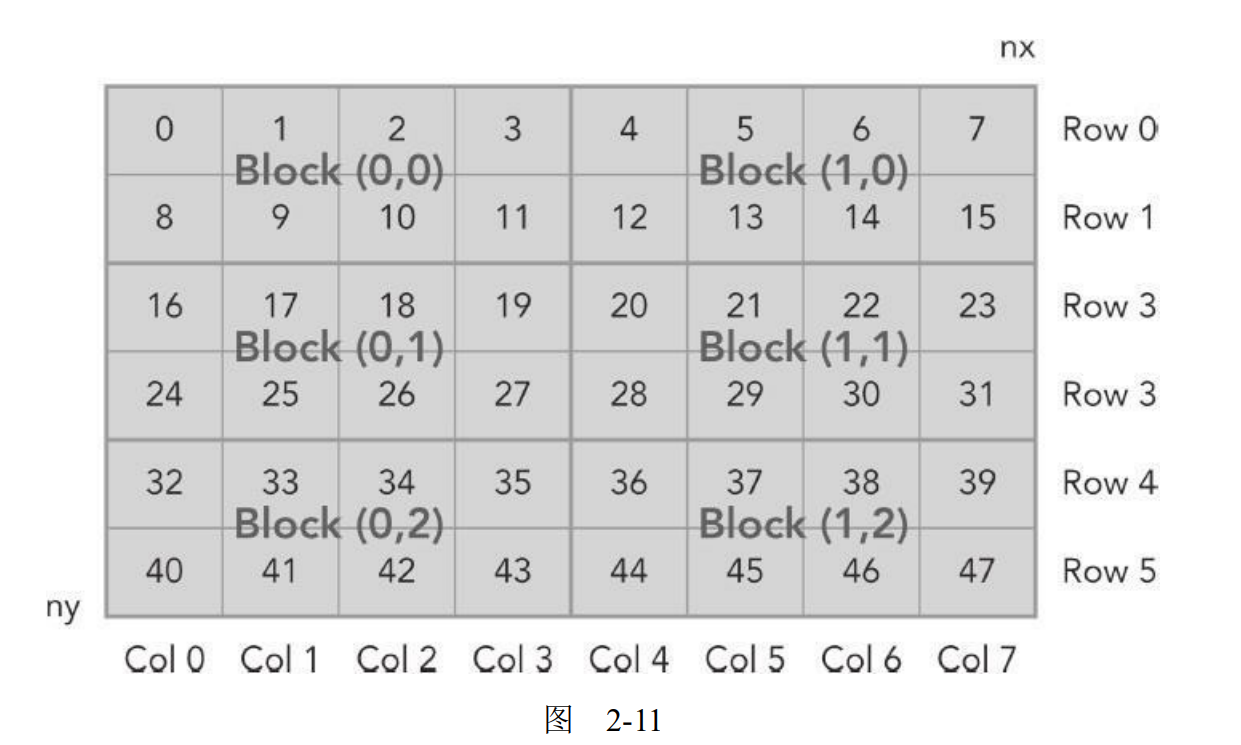
对于每个线程,你可以获取以下信息:
| thread_id(2,1) block_id(1,0) coordinate(6,1) global index 14 ival 14
|
图2-11说明了这三项索引之间的关系。
代码清单2-6 检查块和线程索引(checkT和readIndex.cu)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
| #include <cuda_runtime.h>
#inclde <stdio.h>
#define CHECK(call)
{
const cudaError_t error = call;
if(error != cudaSuccess)
{
printf("Error: %s:%d, ",__FILE__, __LINE__);
printf("code:%d, reason: %s\n",error, cudaGetErrorString(error));
exit(-10*error);
}
}
void initialInt(int *p, int size){
for(int i=0;i<size;i++){
ip[i] = i;
}
}
void printMateix(int *C,const int nx, const int ny){
int *ic = C;
printf("\nMatrix: (%d.%d)\n".nx,ny);
for(int iy=0;iy<ny;iy++){
for(int ix=0; ix<nx;ix++){
printf("%3d",ic[ix]);
}
ic += nx;
printf("\n");
}
printf("\n");
}
__global__ void printThreadIndex(int *A, const int nx, const int ny){
int ix = threadIdx.x + blockIdx.x * blockDim.x;
int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy*nx + ix;
printf("thread_id (%d,%d) block_id (%d,%d) coordinate (%d,%d) global index %2d ival %2d\n", threadIdx.x, threadIdx.y, blockIdx.x,blockIdx.y,ix,iy,idx,A[idx]);
}
int main(int argc,char **argv){
printf("%s Starting...\n",argv[0]);
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
int nx = 8;
int ny = 6;
int nxy = nx*ny;
int nBytes = nxy * sizeof(float);
int *h_A;
h_A = (int *)malloc(nBytes);
initialInt(h_A, nxy);
printMatrix(h_A, nx, ny);
int *d_MatA;
cudaMalloc((void**)&d_MatA, nBytes);
cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice);
dim3 block(4,2);
dim3 grid((nx+block.x-1)/block.x,(ny+block.y-1)/block.y);
printThreadIndex<<<grid,block>>>(d_MatA,nx,ny);
cudaDeviceSynchronize();
cudaFree(d_MatA);
free(h_A);
cudaDeviceReset();
return(0);
}
|
参考资料
CUDA C编程权威指南 程润伟,Max Grossman(美),Ty Mckercher