如何使用AVX和AVX2处理数据(个人翻译)
1.文章来源
Matt Scarpino(USA)
Crunching Numbers with AVX and AVX2 - CodeProject
2.介绍
在2003年,Alex Fr写了一篇优秀的文章[该文章现在已经被原作者删除],解释了如何使用Intel的流式SIMD扩展(SSE)执行SIMD(单指令,多数据)处理。SSE是英特尔处理器支持的一组指令,可对大量数据执行高速运算。
2008年,英特尔推出了一套新的高性能指令,称为高级向量扩展(AVX)。AVX执行许多与SSE指令相同的操作,但以更快的速度对更大的数据块进行操作。最近,英特尔在AVX2和AVX512系列中发布了额外的指令。本文的重点是通过称为intrinsic funtions的特殊C函数访问AVX和AVX2指令。
本文不介绍整个AVX/AVX2 intrinsics,而是侧重于数学计算。特别地,目标是复数相乘。要使用AVX/AVX2执行此操作,需要三种类型的intrinsic:
- Initialization intrinscis
- Arithmetic intrinsics
- Permute/shuffle intrinsics
本文讨论每个类别中的intrinsics,并解释如何在代码中使用它们。本文的最后将展示如何用这些intrinsic进行乘法复数运算。
理解处理器指令和intrinsic function之间的区别是很重要的。AVX指令是执行不可分割操作的汇编命令。例如,AVX指令vaddps添加了两个操作数,并将结果放在第三个操作数中。
要在C/C++中执行操作,the intrinsic funtion _mm256_add_ps()直接映射到vaddps,将汇编的性能与高级函数的便利性结合起来。An intrinsic funtion不一定映射到单个指令,但与其他C/ C++函数相比,AVX/AVX2 intrinsics提供了可靠的高性能。
3.基本要求
要理解本文的内容,您需要基本熟悉C语言和SIMD处理。要执行代码,您需要一个支持AVX或AVX/AVX2的CPU。以下是支持AVX的cpu:
- Intel’s Sandy Bridge/Sandy Bridge E/Ivy Bridge/Ivy Bridge E
- Intel’s Haswell/Haswell E/Broadwell/Broadwell E
- AMD’s Bulldozer/Piledriver/Steamroller/Excavator
支持AVX2的CPU也支持AVX。以下是这些设备:
- Intel’s Haswell/Haswell E/Broadwell/Broadwell E
- AMD’s Excavator
本文中讨论的大多数函数都是由AVX提供的。但也有一些是AVX2特有的。为了区分它们,在本文的表中,我在AVX2 intrinsic的名称前面加上(2)。
[个人补充]
判断自己电脑CPU是否支持AVX和AVX2,最简单的就是在命令行执行以下命令:
1 | |
你会得到以下结果:
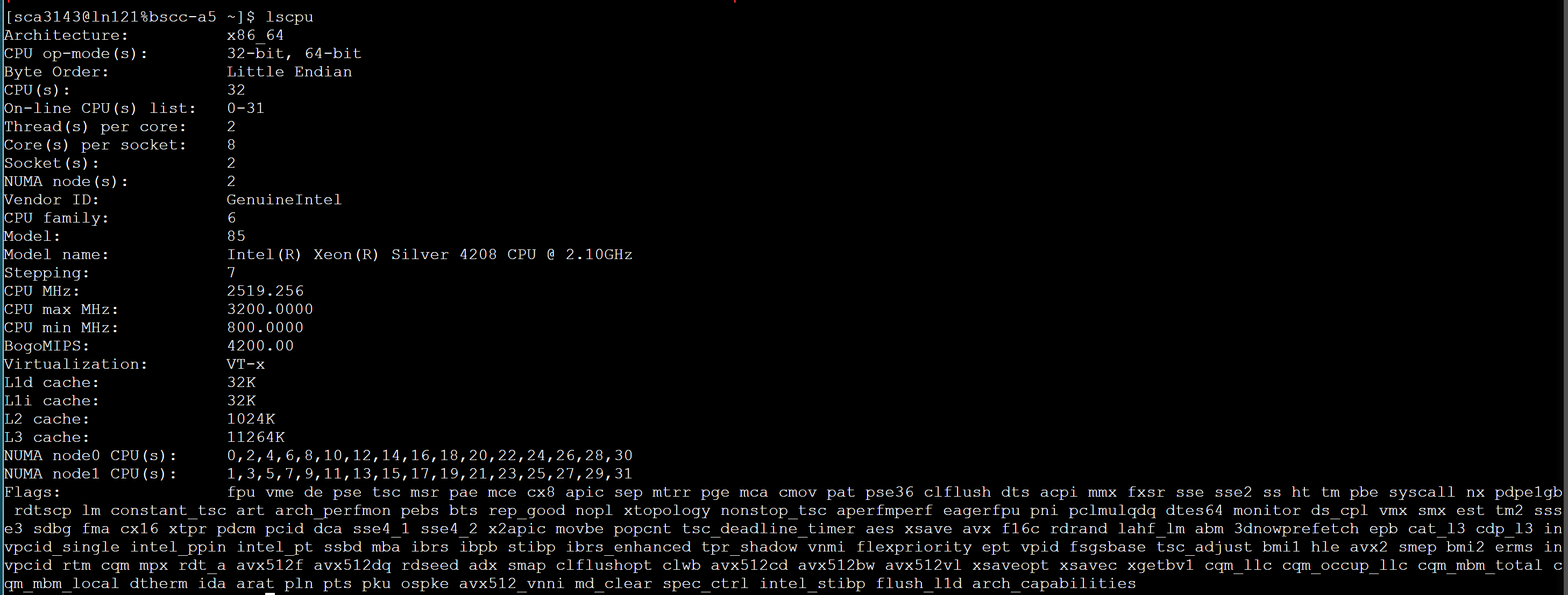
在Flags里面你可以清楚的看到你的电脑是否支持AVX以及AVX2。
4.向量化概述
AVX指令通过同时处理大块值而不是单独处理值来提高应用程序的性能。这些值大块称为向量,AVX向量最多可以包含256位数据。
常见的AVX向量包含4个double (4 x 64位= 256),8个float (8 x 32位= 256)或8个int (8 x 32位= 256)。[double 8B, flout 4B, int 4B]
一个示例将演示AVX/AVX2处理的强大功能。假设一个函数需要将一个数组的8个浮点数乘以第二个数组的8个浮点数,并将结果添加到第三个数组。如果没有向量化,函数可能是这样的:
1 | |
下面是使用AVX2函数的例子:
1 | |
This AVX2 intrinsic funtion _mm256_fmadd_ps处理24个floats,但它不映射到单个指令。相反,它执行三个指令:vfmadd132ps、vfmadd213ps和vfmadd231ps。尽管如此,它执行得很快,比遍历单个元素快得多。
尽管英特尔的intrinsics功能强大,但它们还是让许多程序员感到紧张。这通常有两个原因。首先,数据类型有奇怪的名字,比如**__m256。其次,函数有奇怪的名称,如_mm256_fmadd_ps**。因此,在详细讨论intrinsic funtions之前,我想先讨论一下Intel的数据类型和命名约定。
5.AVX编程基础
本文主要关注AVX和AVX2提供的与数学相关的intrinsic functions。但在看函数之前,有三点很重要:
- Data types
- Function naming conventions
- Compiling AVX applications
本节涉及这些要点,并提供一个简单的应用程序,用于一个向量减去另一个向量。
5.1数据类型
少数intrinsic接受传统的数据类型,如int或float,但大多数intrinsic操作有特定的AVX和AVX2的数据类型。有六种主要的向量类型,表1列出了它们。
Table 1:AVX/AVX2 Data Types
| Data Type | Description |
|---|---|
__m128 | 128-bit vector containing 4 floats |
__m128d | 128-bit vector containing 2 doubles |
__m128i | 128-bit vector containing integers |
__m256 | 256-bit vector containing 8 floats |
__m256d | 256-bit vector containing 4 doubles |
__m256i | 256-bit vector containing integers |
每种类型都以两个下划线、一个m和向量的宽度(以位为单位)开始。AVX512支持以_m512开头的512位向量类型,但AVX/AVX2向量不超过256位。如果向量类型以d结尾,则代表double,如果没有后缀,则代表float。看起来_m128i和_m256i向量必须包含int型,但事实并非如此。整数向量类型可以包含任何类型的整数,from chars to shorts to unsigned long longs.That is, an _m256i may contain 32 chars, 16 shorts, 8 ints, or 4 longs. These integers can be signed or unsigned.
5.3函数命名约定
AVX/AVX2 intrinsics的名称一开始可能令人困惑,但命名约定确是非常直白的。一旦你理解了它,你就可以通过看它的名字来大致判断一个函数是做什么的。AVX/AVX2 intrinsics的一般形式如下:
_mm
该格式的各部分如下所示:
<bit_width>identifies the size of the vector returned by the function. For 128-bit vectors, this is empty. For 256-bit vectors, this is set to256.<name>describes the operation performed by the intrinsic<data_type>identifies the data type of the function’s primary arguments
最后一部分
ps- vectors containfloats (psstands for packed single-precision)pd- vectors containdoubles (pdstands for packed double-precision)epi8/epi16/epi32/epi64- vectors contain 8-bit/16-bit/32-bit/64-bit signed integersepu8/epu16/epu32/epu64- vectors contain 8-bit/16-bit/32-bit/64-bit unsigned integerssi128/si256- unspecified 128-bit vector or 256-bit vectorm128/m128i/m128d/m256/m256i/m256d- identifies input vector types when they’re different than the type of the returned vector
例如,考虑_mm256_srlv_epi64。即使您不知道srlv是什么意思,_mm256前缀告诉您该函数返回一个256位向量,_epi64告诉您参数包含64位有符号整数。
作为第二个示例,考虑_mm_testnzc_ps。_mm表示函数返回一个128位的向量。末尾的_ps表示参数向量包含浮点数。
AVX数据类型以两个下划线和一个m开头。函数以一个下划线和两个m开头。我很容易搞混这一点,所以我想出了一种方法来记住它们的区别:数据类型代表内存(memory),函数代表多媒体操作(multimedia)。这是我能做的最好的了。
5.4构建AVX应用程序
要构建使用AVX intrinsic的应用程序,不需要链接任何库。但是您需要包含imminrin .h头文件。此头文件包括将AVX/AVX2函数映射到指令的其他头文件。
hello_avx.c中的代码显示了一个基本的AVX应用程序的样子:
1 | |
要构建应用程序,需要告诉编译器该体系结构支持AVX。这个标志取决于编译器,gcc需要-mavx标志。因此,可以使用以下命令编译hello_avx.c源文件:
1 | |
在本例中,所有函数都以_mm256开始,以_ps结束,因此我希望所有操作都清楚地涉及包含floats的256位向量。我还希望结果向量中的每个元素都等于1.0。如果运行应用程序,您将看到情况就是这样。
[这就是一个简单的向量减法例子,大家可以对应数据看一下]
1 | |
5.5初始化intrinsics
在对AVX向量进行操作之前,需要用数据填充向量。因此,本文讨论的第一组intrinsics用数据初始化向量。有两种方法:用标量值初始化向量和用从内存加载的数据初始化向量。
5.5.1使用标量值初始化
AVX提供了将一个或多个值组合成256位向量的intrinsics funtions。表2列出了它们的名称,并提供了每个名称的描述。也有类似的intrinsics初始化128位向量,但它们是由SSE提供的,而不是AVX。函数名的唯一区别是_mm256_被替换为_mm_。
Table 2: Initialization Intrinsics
| Function | Description |
|---|---|
_mm256_setzero_ps/pd | Returns a floating-point vector filled with zeros |
_mm256_setzero_si256 | Returns an integer vector whose bytes are set to zero |
_mm256_set1_ps/pd | Fill a vector with a floating-point value |
_mm256_set1_epi8/epi16 _mm256_set1_epi32/epi64 | Fill a vector with an integer |
_mm256_set_ps/pd | Initialize a vector with eight floats (ps) or four doubles (pd) |
_mm256_set_epi8/epi16 _mm256_set_epi32/epi64 | Initialize a vector with integers |
_mm256_set_m128/m128d/ _mm256_set_m128i | Initialize a 256-bit vector with two 128-bit vectors |
_mm256_setr_ps/pd | Initialize a vector with eight floats (ps) or four doubles (pd) in reverse order |
_mm256_setr_epi8/epi16 _mm256_setr_epi32/epi64 | Initialize a vector with integers in reverse order |
表中的第一个函数是最容易理解的。_m256_setzero_ps返回一个__m256向量,包含8个设置为0的浮点数。类似地,_m256_setzero_si256返回一个__m256i向量,其字节被设置为0。例如,下面这行代码创建了一个256位的向量,其中包含4个设为0的double:
1 | |
名称中包含set1的函数接受一个值,并在整个向量中重复该值。例如,下面这行代码创建了一个__m256i,它的16个short value被设置为47:
1 | |
表2中的其他函数包含_set_或_setr_。这些函数接受一系列值,每个向量的元素对应一个值。这些值被放置在返回的向量中,理解顺序很重要。下面的函数调用返回一个包含8个整数的向量,其值范围为1到8:
1 | |
您可能希望值按照给定的顺序存储。但英特尔的架构是小端存储类型的[这里很重要],所以最低有效值(8)先存储,最高有效值(1)最后存储。您可以通过将int_vector转换为int指针并打印存储的值来验证这一点。如下代码所示:
1 | |
如果希望值按给定顺序存储,可以使用_setr_函数之一创建向量,其中r可能代表reverse。下面的代码展示了它是如何工作的:
1 | |
有趣的是,AVX和AVX2都没有提供用无符号整数初始化向量的intrinsic。但是,它们提供了对带无符号整数的向量进行操作的函数。
5.5.2从内存加载数据
AVX/AVX2的一个常见用法是将数据从内存加载到向量中,对向量进行处理,并将结果存储回内存。第一步是使用表3中列出的intrinsic funtions完成的。最后两个函数前面有(2),因为它们是由AVX2而不是AVX提供的。
Table 3: Vector Load Intrinsics
| Data Type | Description |
|---|---|
_mm256_load_ps/pd | Loads a floating-point vector from an aligned memory address |
_mm256_load_si256 | Loads an integer vector from an aligned memory address |
_mm256_loadu_ps/pd | Loads a floating-point vector from an unaligned memory address |
_mm256_loadu_si256 | Loads an integer vector from an unaligned memory address |
_mm_maskload_ps/pd _mm256_maskload_ps/pd | Load portions of a 128-bit/256-bit floating-point vector according to a mask |
(2)_mm_maskload_epi32/64 (2)_mm256_maskload_epi32/64 | Load portions of a 128-bit/256-bit integer vector according to a mask |
当将数据加载到向量中时,内存对齐变得特别重要。每个_mm256_load_* intrinsic接受一个必须在32字节边界上对齐的内存地址。即地址必须能被32整除。下面的代码展示了如何在实践中使用它:
1 | |
【个人补充】关于内存对齐以及相关函数
内存对齐 - Amicoyuan (xingyuanjie.top)
AVX向量化学习(二)-内存对齐的应用 - Amicoyuan (xingyuanjie.top)
任何使用_m256_load_*加载未对齐数据的尝试都会造成segmentation fault。如果数据不是以32位边界对齐,则应该使用_m256_loadu_*函数。如下代码所示:
1 | |
假设你想用AVX向量处理一个浮点数组(float),但是数组的长度是11,不能被8整除。在这种情况下,第二个__m256向量的最后五个浮点数需要设置为0[或者使用非向量计算手段],这样它们就不会影响计算。这种选择性加载可以用表3底部的**_maskload_**函数来完成。
每个_maskload_函数接受两个参数:一个内存地址和一个与返回向量元素数量相同的整数向量。对于整数向量中最高位为1的每个元素,将从内存中读取返回向量中相应的元素。如果整数向量中的最高位为零,则返回向量中的相应元素被设置为零。
一个示例将说明如何使用这些函数。mask_load.c中的代码将8个整型读入一个向量,最后3个应该设置为0。要使用的函数是_mm256_maskload_epi32,它的第二个参数应该是__m256i掩码向量。这个掩码向量包含5个最高位为1的整数和3个最高位为0的整数。下面是代码的样子:
【int型在计算机的存储是补码,正数的补码最高位为0,所以这里返回0,负数的补码最高位为1,所以这里返回的是内存中相应的元素】
1 | |
如果您在支持AVX2的系统上运行此应用程序,它将打印以下结果:
1 | |
有三点是需要注意的:
- 代码使用_setr_函数而不是_set_来设置掩码向量的内容,因为它在将向量元素传递给函数时对它们进行排序。
- 负整数的最高位总是1。这就是掩码向量包含五个负数和三个正数的原因。
- _mm256_maskload_epi32函数由AVX2提供,而不是AVX。因此,要用gcc编译这段代码,必须使用-mavx2标志而不是-mavx。
除了表3中列出的函数之外,AVX2还提供了从内存加载索引数据的集合函数。
6.Arithmetic Intrinsics
数学是AVX存在的主要原因,基本操作是加、减、乘和除。本节将介绍执行这些操作的intrinsic funtions,还将介绍AVX2提供的新的融合乘法和加法函数。
6.1加法和减法
表4列出了执行加法和减法的AVX/AVX2 intrinsic。由于考虑到饱和度,它们大多数都作用于包含整数的向量。
Table 4: Addition and Subtraction Intrinsics
| Data Type | Description |
|---|---|
_mm256_add_ps/pd | Add two floating-point vectors |
_mm256_sub_ps/pd | Subtract two floating-point vectors |
(2)_mm256_add_epi8/16/32/64 | Add two integer vectors |
(2)_mm236_sub_epi8/16/32/64 | Subtract two integer vectors |
(2)_mm256_adds_epi8/16 (2)_mm256_adds_epu8/16 | Add two integer vectors with saturation |
(2)_mm256_subs_epi8/16 (2)_mm256_subs_epu8/16 | Subtract two integer vectors with saturation |
_mm256_hadd_ps/pd | Add two floating-point vectors horizontally |
_mm256_hsub_ps/pd | Subtract two floating-point vectors horizontally |
(2)_mm256_hadd_epi16/32 | Add two integer vectors horizontally |
(2)_mm256_hsub_epi16/32 | Subtract two integer vectors horizontally |
(2)_mm256_hadds_epi16 | Add two vectors containing shorts horizontally with saturation |
(2)_mm256_hsubs_epi16 | Subtract two vectors containing shorts horizontally with saturation |
_mm256_addsub_ps/pd | Add and subtract two floating-point vectors |
加法和减法整数向量时,重要的是要查看_add_/_sub_函数和_adds_/_subs_函数之间的区别。额外的s代表饱和,当结果需要的内存超过向量可以存储的内存时,就会产生饱和。Functions that take saturation into account clamp the result to the minimum/maximum value that can be stored.没有饱和的函数在发生饱和时忽略内存问题。
例如,假设一个向量包含有符号字节,那么每个元素的最大值是127 (0x7F)。如果一个运算将98加到85,数学和是183 (0xB7)。
- 如果使用_mm256_add_epi8添加这些值,饱和度将被忽略,存储的结果将是-73 (0xB7)。
- 如果使用_mm256_adds_epi8添加这些值,结果将被固定为最大值127 (0x7F)。
作为另一个例子,考虑两个包含有符号短整数的向量。最小值为-32,768。如果计算-18,000 - 19,000,数学结果是-37,000 (0xFFFF6F78作为32位整数)。
- 如果用_mm256_sub_epi16减去这些值,饱和度将被忽略,存储的结果将是28,536 (0x6F78)。
- 如果用_mm256_subs_epi16减去这些值,结果将被压缩到最小值-32,768 (0x8000)。
_hadd_/_hsub_函数水平执行加法和减法。也就是说,它们不是添加或减去不同向量的元素,而是在每个向量中添加或减去相邻的元素。结果以交错的方式存储。图1显示了_mm256_hadd_pd的工作原理,它水平地添加了两个向量A和B:
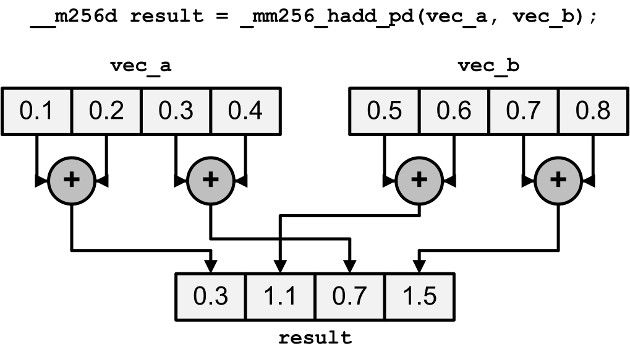
Figure 1: Horizontal Addition of Two Vectors
水平加减元素看起来可能很奇怪,但这些操作在复数相乘时很有用。本文稍后将对此进行解释。表4中的最后一个函数_mm256_addsub_ps/pd交替减法和加法两个浮点向量的元素。也就是说,偶数元素被减去,奇数元素被加上。例如,如果vec_a包含(0.1,0.2,0.3,0.4),vec_b包含(0.5,0.6,0.7,0.8),则_mm256_addsub_pd(vec_a, vec_b)等于(-0.4,0.8,-0.4,1.2)【需要注意数组下标从0开始】。
6.2乘法和除法
表5列出了执行乘法和除法的AVX/AVX2 intrinsic。与加法和减法一样,对整数进行运算也有一些特殊的特性。
Table 5: Multiplication and Division Intrinsics
| Data Type | Description |
|---|---|
_mm256_mul_ps/pd | Multiply two floating-point vectors |
(2)_mm256_mul_epi32/ (2)_mm256_mul_epu32 | Multiply the lowest four elements of vectors containing 32-bit integers |
(2)_mm256_mullo_epi16/32 | Multiply integers and store low halves |
(2)_mm256_mulhi_epi16/ (2)_mm256_mulhi_epu16 | Multiply integers and store high halves |
(2)_mm256_mulhrs_epi16 | Multiply 16-bit elements to form 32-bit elements |
_mm256_div_ps/pd | Divide two floating-point vectors |
如果两个N位的数字在计算机上相乘,结果可以占用2N位【这里你需要熟悉计算机组成原理中的乘法原理,同时思考会不会在某些函数出现精度损失的情况】。因此,只有_mm256_mul_epi32和_mm256_mul_epu32的四个低元素被乘在一起,结果是一个包含四个长整数的向量。
___m256i _mm256_mul_epi32 (m256i a, __m256i b)
Description
Multiply the low signed 32-bit integers from each packed 64-bit element in a and b, and store the signed 64-bit results in dst.
Operation
1 | |
图2:整数向量的低元素相乘
_mullo_函数类似于整数_mul_函数,但它们不是乘低元素,而是乘两个向量的每个元素,只存储每个乘积的低一半。
Synopsis
m256i _mm256_mullo_epi32 (m256i a, __m256i b)
#include <immintrin.h>
Instruction: vpmulld ymm, ymm, ymm
CPUID Flags: AVX2
Description
Multiply the packed signed 32-bit integers in a and b, producing intermediate 64-bit integers, and store the low 32 bits of the intermediate integers in dst.
Operation
1 | |
图3:整数相乘和存储低二分之一
_mm256_mulhi_epi16和_mm256_mulhi_epu16 intrinsics类似,但是它们存储整数积的高一半。
Synopsis
m256i _mm256_mulhi_epi16 (m256i a, __m256i b)
#include <immintrin.h>
Instruction: vpmulhw ymm, ymm, ymm
CPUID Flags: AVX2
Description
Multiply the packed signed 16-bit integers in a and b, producing intermediate 32-bit integers, and store the high 16 bits of the intermediate integers in dst.
Operation
1 | |
6.3Fused Multiply and Add (FMA)
如前所述,两个N位数字相乘的结果可以占用2N位。因此,当您将两个浮点值a和b相乘时,结果实际上是四舍五入(a * b),其中四舍五入(x)返回最接近x的浮点值。随着进一步操作的执行,这种精度损失会增加。【这里需要注意分部乘加,先乘法后加法和使用FMA两者的计算精度】
AVX2提供了将乘法和加法融合在一起的指令。也就是说,它们不是返回整数(整数(a * b) + c),而是返回整数(a * b + c)。因此,这些指令比分别执行乘法和加法提供了更高的速度和准确性【这里正是FMA的特点】。
表6列出了AVX2提供的FMA intrinsic,并包括对每个函数的描述。表中的每条指令都接受三个输入向量,我把它们分别称为a、b和c。
Table 6: FMA Intrinsics
| Data Type | Description |
|---|---|
(2)_mm_fmadd_ps/pd/ (2)_mm256_fmadd_ps/pd | Multiply two vectors and add the product to a third (res = a * b + c) |
(2)_mm_fmsub_ps/pd/ (2)_mm256_fmsub_ps/pd | Multiply two vectors and subtract a vector from the product (res = a * b - c) |
(2)_mm_fmadd_ss/sd | Multiply and add the lowest element in the vectors (res[0] = a[0] * b[0] + c[0]) |
(2)_mm_fmsub_ss/sd | Multiply and subtract the lowest element in the vectors (res[0] = a[0] * b[0] - c[0]) |
(2)_mm_fnmadd_ps/pd (2)_mm256_fnmadd_ps/pd | Multiply two vectors and add the negated product to a third (res = -(a * b) + c) |
(2)_mm_fnmsub_ps/pd/ (2)_mm256_fnmsub_ps/pd | Multiply two vectors and add the negated product to a third (res = -(a * b) - c) |
(2)_mm_fnmadd_ss/sd | Multiply the two lowest elements and add the negated product to the lowest element of the third vector (res[0] = -(a[0] * b[0]) + c[0]) |
(2)_mm_fnmsub_ss/sd | Multiply the lowest elements and subtract the lowest element of the third vector from the negated product (res[0] = -(a[0] * b[0]) - c[0]) |
(2)_mm_fmaddsub_ps/pd/ (2)_mm256_fmaddsub_ps/pd | Multiply two vectors and alternately add and subtract from the product (res = a * b - c) |
(2)_mm_fmsubadd_ps/pd/ (2)_mmf256_fmsubadd_ps/pd | Multiply two vectors and alternately subtract and add from the product (res = a * b - c) |
如果一个内征的名称以_ps或_pd结尾,则输入向量的每个元素都包含在运算中。如果intrinsic的名称以_ss或_sd结尾,则只包括最低的元素。输出向量中的其余元素被设置为与第一个输入向量中的元素相等。例如,假设vec_a = (1.0, 2.0), vec_b = (5.0, 10.0), vec_c =(7.0, 14.0)。在本例中,_mm_fmadd_sd(vec_a, vec_b, vec_c)返回(12.0,2.0),因为(1.0 * 5.0)+ 7.0 = 12.0,2.0是vec_a的第二个元素。
了解_fmadd_/_fmsub_和_fnmadd_/_fnmsub_ intrinsic之间的区别很重要。后一种函数在加上或减去第三个输入向量之前,对前两个输入向量的乘积求反。
Synopsis
__m256d _mm256_fnmadd_pd (m256d a, m256d b, m256d c)
#include <immintrin.h>
Instruction: vfnmadd132pd ymm, ymm, ymm
vfnmadd213pd ymm, ymm, ymm
vfnmadd231pd ymm, ymm, ymm
CPUID Flags: FMA
Description
Multiply packed double-precision (64-bit) floating-point elements in a and b, add the negated intermediate result to packed elements in c, and store the results in dst.
Operation
1 | |
_fmaddsub_和_fmsubadd_内在函数在第三个向量的加法和减法元素之间交替使用。_fmaddsub_ intrinsic奇数元素做加法而偶数元素做减法。_fmsubadd_ intrinsic奇数元素做减法而偶数元素做加法。fmatest.c中的代码展示了如何在实践中使用_mm256_fmaddsub_pd intrinsic。
1 | |
当这段代码在支持AVX2的处理器上编译和执行时,打印的结果如下:
1 | |
FMA指令是由AVX2提供的,因此您可能认为使用gcc构建应用程序需要使用-mavx2标志。但是我发现-mfma标志是必需的。否则,我会得到奇怪的编译错误。
7.Permuting and Shuffling
许多应用程序必须重新排列向量元素,以确保正确执行操作。
AVX/AVX2为此目的提供了许多intrinsic funtion,其中两大类是_permute_函数和_shuffle_函数。本节介绍这两种类型的intrinsic。
7.1Permuting
AVX提供了返回一个向量的函数,该向量包含一个向量的重新排列的元素。表7列出了这些排列函数,并提供了对每个函数的描述。
Table 7: Permute Intrinsics
| Data Type | Description |
|---|---|
_mm_permute_ps/pd/ _mm256_permute_ps/pd | Select elements from the input vector based on an 8-bit control value |
(2)_mm256_permute4x64_pd/ (2)_mm256_permute4x64_epi64 | Select 64-bit elements from the input vector based on an 8-bit control value |
_mm256_permute2f128_ps/pd | Select 128-bit chunks from two input vectors based on an 8-bit control value |
_mm256_permute2f128_si256 | Select 128-bit chunks from two input vectors based on an 8-bit control value |
_mm_permutevar_ps/pd _mm256_permutevar_ps/pd | Select elements from the input vector based on bits in an integer vector |
(2)_mm256_permutevar8x32_ps/ (2)_mm256_permutevar8x32_epi32 | Select 32-bit elements (floats and ints) using indices in an integer vector |
_permute_ intrinsic接受两个参数:一个输入向量和一个8位控制值。控制值的位决定输入向量的哪个元素插入到输出中。
对于_mm256_permute_ps,每对控制位通过选择输入向量中的一个上或下元素来确定一个上或下输出元素。
1 | |
1 | |
Figure 4: Operation of the Permute Intrinsic Function
如图所示,输入向量的值可以在输出中重复多次。其他输入值可能根本不被选择。
在_mm256_permute_pd中,控制值的低四位在相邻的双精度数对之间进行选择。_mm256_permute4x4_pd类似,但使用所有控制位来选择将哪个64位元素放在输出中。在_permute2f128_ intrinsic中,控制值从两个输入向量中选择128位块,而不是从一个输入向量中选择元素。
_permutevar_ intrinsic执行与_permute_ intrinsic相同的操作。但是它们不是使用8位控制值来选择元素,而是依赖于与输入向量大小相同的整数向量。例如,_mm256_permute_ps的输入向量是_mm256,因此整数向量是_mm256i。整数向量的高位执行选择的方式与_permute_ intrinsic的8位控制值的位相同。
7.2Shuffling
像_permute_ intrinsic一样,_shuffle_ intrinsic从一个或两个输入向量中选择元素,并将它们放在输出向量中。表8列出了这些功能,并提供了每个功能的描述。
Table 8: Shuffle Intrinsics
| Data Type | Description |
|---|---|
_mm256_shuffle_ps/pd | Select floating-point elements according to an 8-bit value |
_mm256_shuffle_epi8/ _mm256_shuffle_epi32 | Select integer elements according to an 8-bit value |
(2)_mm256_shufflelo_epi16/ (2)_mm256_shufflehi_epi16 | Select 128-bit chunks from two input vectors based on an 8-bit control value |
所有的shuffle_ intrinsic运算于256位向量。在每种情况下,最后一个参数是一个8位的值,它决定哪些输入元素应该放在输出向量中。
对于_mm256_shuffle_ps,只使用控件值的高四位。如果输入向量包含整型或浮点数,则使用所有控制位。对于_mm256_shuffle_ps,前两对位选择第一个向量中的元素,后两对位选择第二个向量中的元素。
Synopsis
m256 _mm256_shuffle_ps (m256 a, __m256 b, const int imm8)
#include <immintrin.h>
Instruction: vshufps ymm, ymm, ymm, imm8
CPUID Flags: AVX
Description
Shuffle single-precision (32-bit) floating-point elements in a within 128-bit lanes using the control in imm8, and store the results in dst.
Operation
1 | |
为了shuffle16位值,AVX2提供了_mm256_shufflelo_epi16和_mm256_shufflehi_epi16。与_mm256_shuffle_ps一样,控制值被分成四对从八个元素中选择的位。但是对于_mm256_shufflelo_epi16, 8个元素是从8个低的16位值中取出的。对于_mm256_shufflehi_epi16, 8个元素取自8个高的16位值。
8.Complex Multiplication
在信号处理应用中,复数乘法是一项必须反复执行的耗时操作。我不会深入讨论这个理论,但每个复数都可以表示为a + bi,其中a和b是浮点值,i是-1的平方根。A是实部,b是虚部。如果(a + bi)和(c + di)相乘,乘积等于(ac - bd) + (ad + bc)i。
复数可以以交错的方式存储,这意味着每个实数部分后面跟着虚数部分。假设vec1是一个__m256d,存储两个复数(a + bi)和(x + yi), vec2是一个__m256d,存储(c + di)和(z + wi)。图6说明了如何存储这些值。如图所示,prod向量存储了两个产物:(ac - bd) + (ad + bc)i和(xz - yw) + (xw + yz)i。
【图片丢失】
Figure 6: Complex Multiplication Using Vectors
我不知道用AVX/AVX2计算复杂乘积的最快方法。但我想出了一个方法,效果很好。它包括五个步骤:
- 将vec1和vec2相乘,并将结果存储在vec3中。
- 切换vec2的实/虚值。
- 求vec2的虚数的负数。
- 将vec1和vec2相乘,并将结果存储在vec4中。
- 对vec3和vec4进行水平相减,得到vec1中的答案。
complex_multi .c中的代码展示了如何使用AVX intrinsic执行此操作:
1 | |
1 | |
这段代码作用于双向量,但是可以很容易地扩展该方法以支持浮点向量。
9.Points of Interest
许多开发人员可能会避免学习AVX/AVX2,希望编译器能够执行自动向量化。自动向量化是一个很好的特性,但是如果您了解本质,就可以重新安排算法以更好地利用SIMD处理。通过插入AVX/AVX2 intrinsic,我极大地提高了信号处理应用程序的处理速度。
10.History
2/20 - Fixed formatting and image links
4/2 - Fixed a couple typographical errors
11.License
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
Written By
 United States
United States
I’ve been a programmer and engineer for over 20 years. I’m a certified Azure Developer Associate and an Azure IoT Developer Specialist.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!