CMU 15-213 Lecture 01:Course Overview
2015 CMU 15-213 CSAPP 深入理解计算机系统 Lecture 01: Course Overview
例子一:
1 | |
1 | |
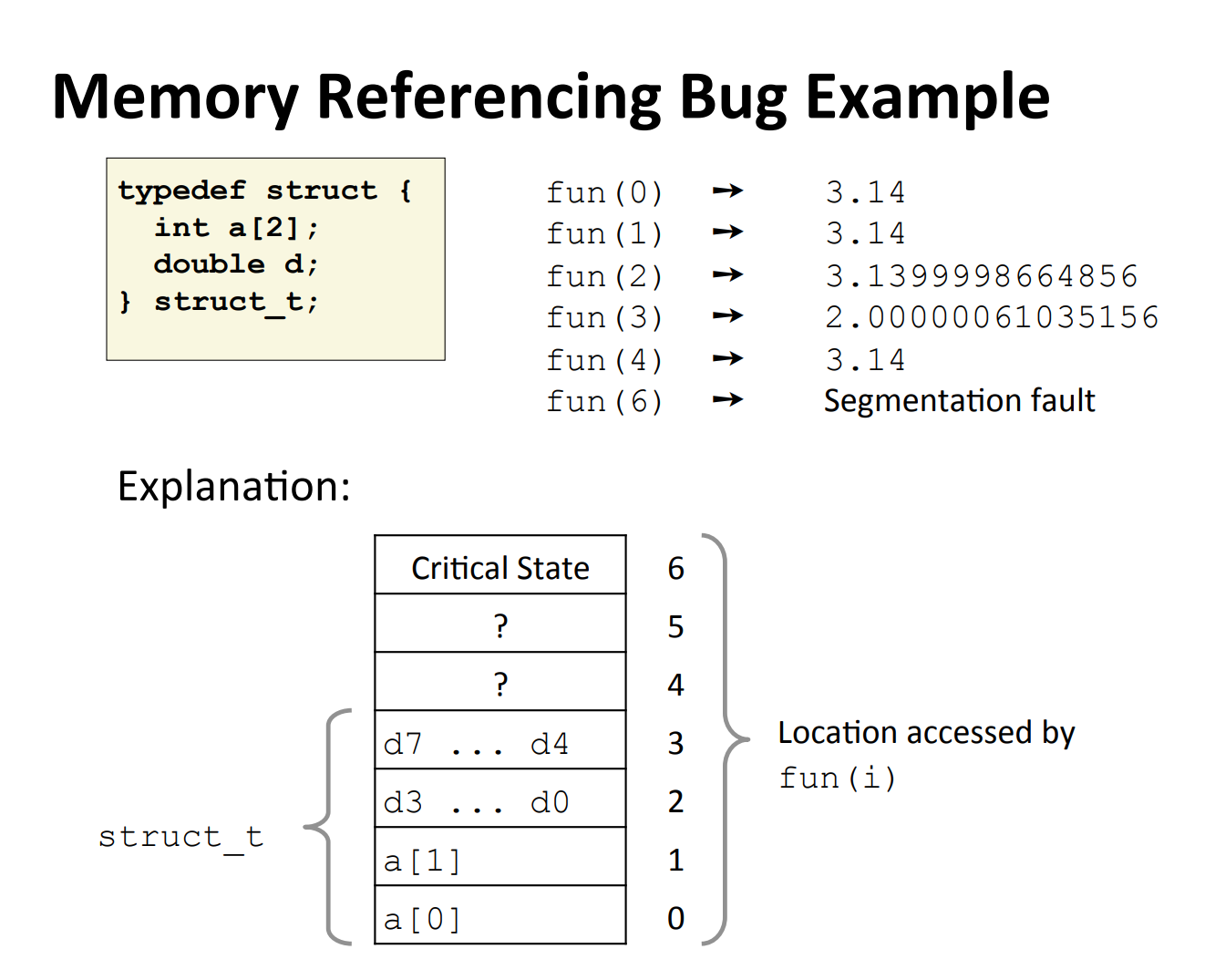
【图中假设memory line大小为4B】根据结构体可知我们拥有一个int型的数组大小为2,一个double型的变量。因为int数组的大小为2,当fun(0),fun(1)时,s.a[i]访问是正确的,所以fun(0),fun(1)返回正确值s.d及3.14。而当fun(i):i>1时,就会返回奇怪的结果,这是因为数组大小为2,我们越界了,实际上s.a[i]写的是double的内存空间,如图中的2,3。而6代表程序状态,我们去修改它就会造成程序状态的改变,导致Segmentation fault。这里提醒我们在写C代码的时候一定要注意边界处理。【这里需要清楚C语言中堆区和栈区存的是什么】
例子二:
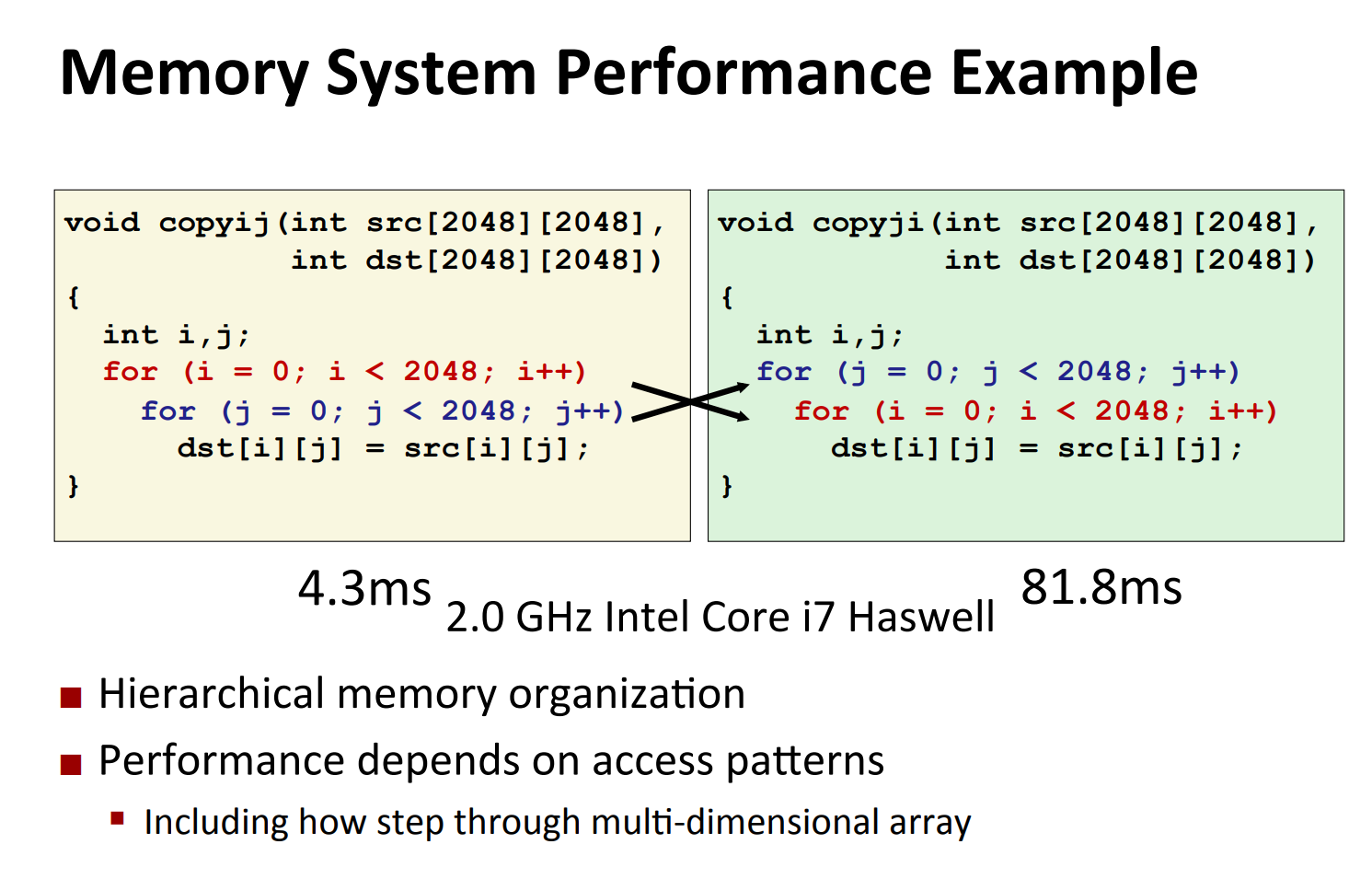
【src和dst是大小2048*2048的二维数组】上面的图片,我们可以十分清楚代码的逻辑。他想把src数组的值拷贝到dst。而左右代码的功能完全一样,仅仅是for循环顺序不一样,但是却会有这么大的性能差距,这是什么原因呢?总的来说就是左边代码cache命中率高,右边cache命中率的。cache命中和cache miss的速度差距很大甚至是数量级别的差距,这是导致两者差距巨大的原因。【注意这里还可以更细致的分析,但是会有很多其他因素会影响】
参考资料
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!