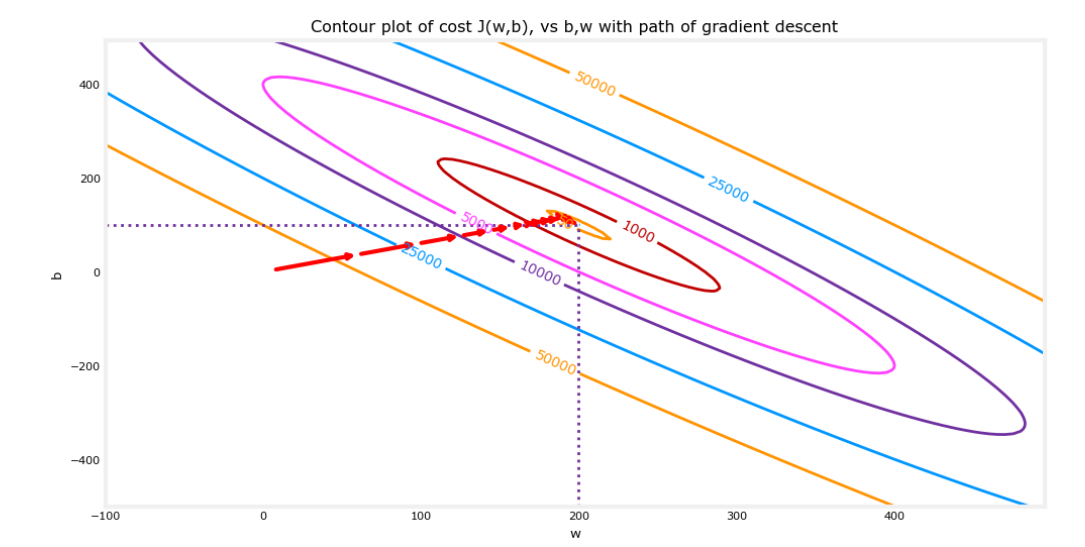
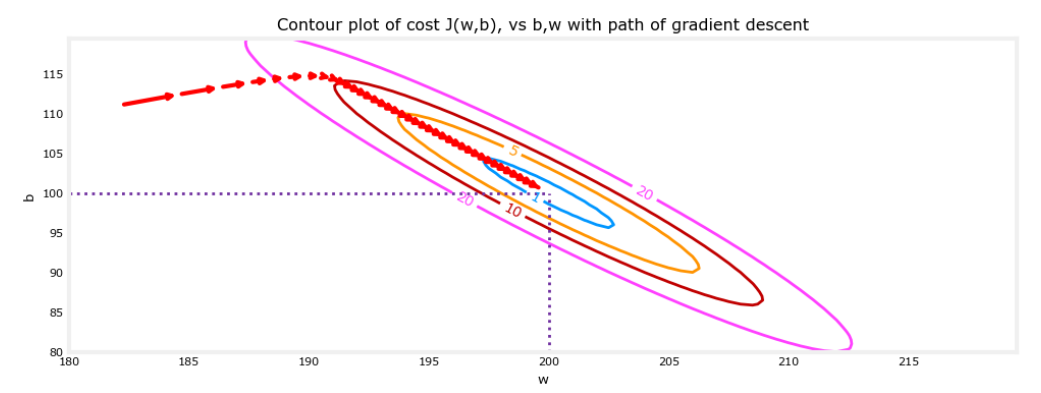
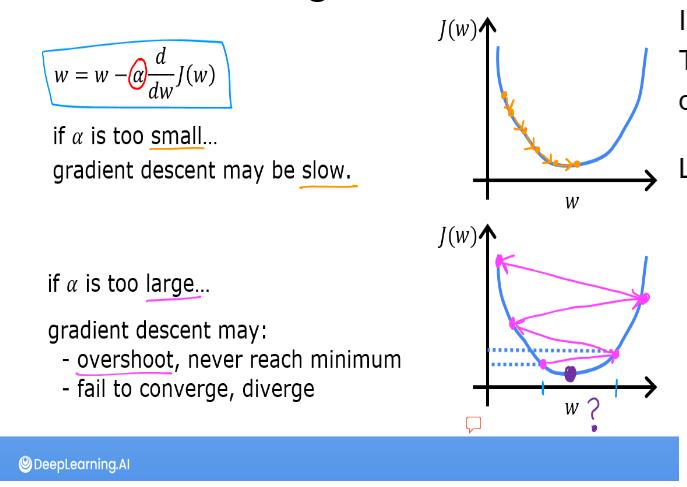
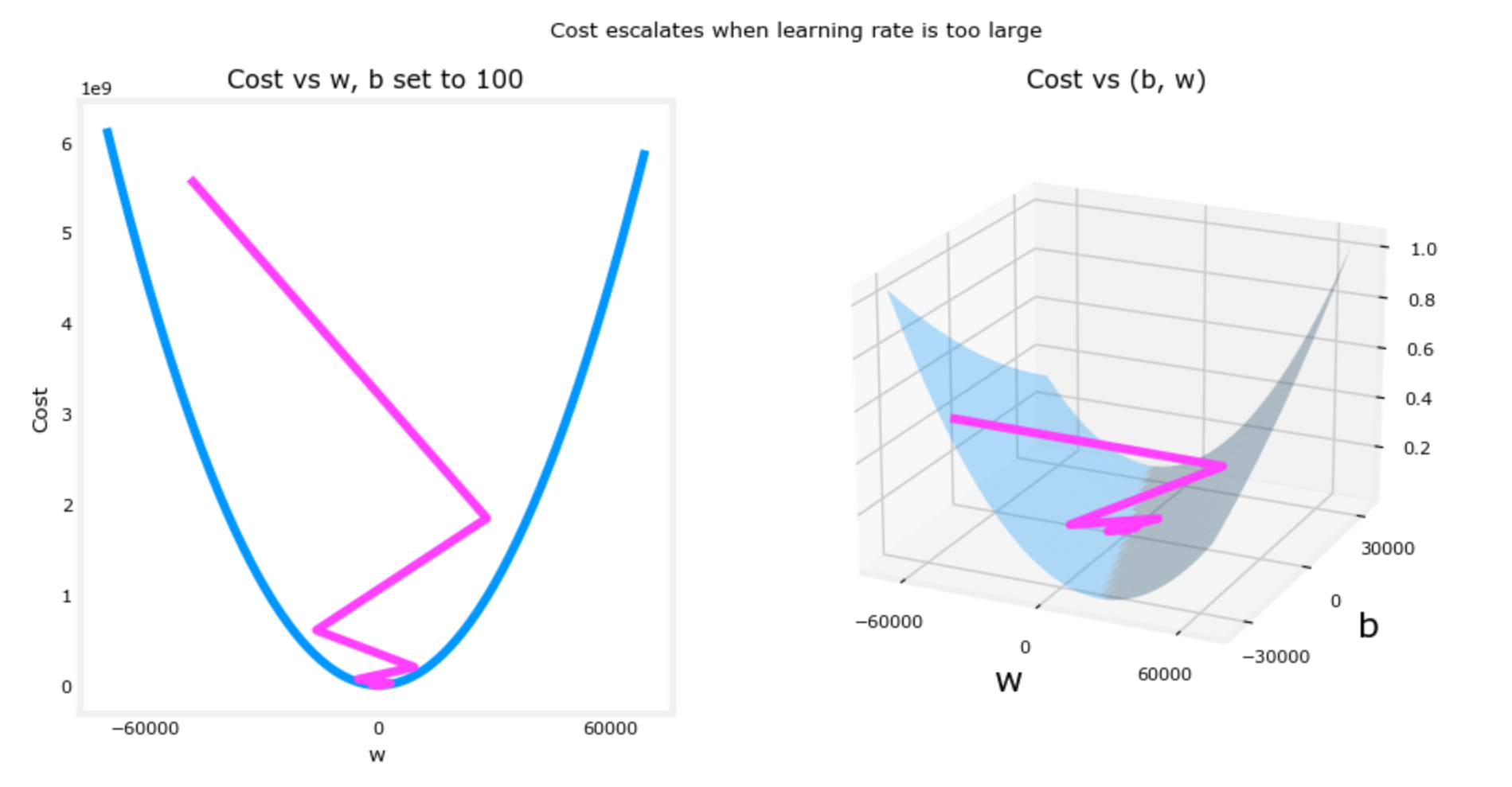
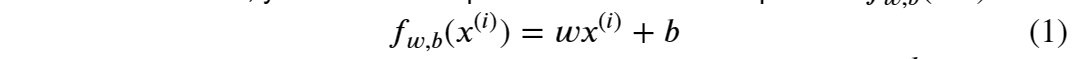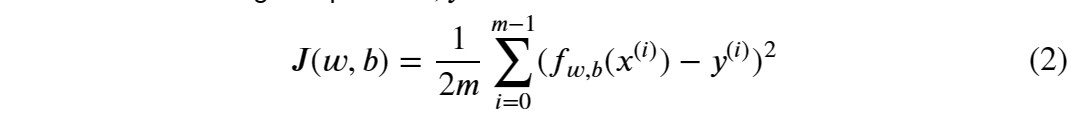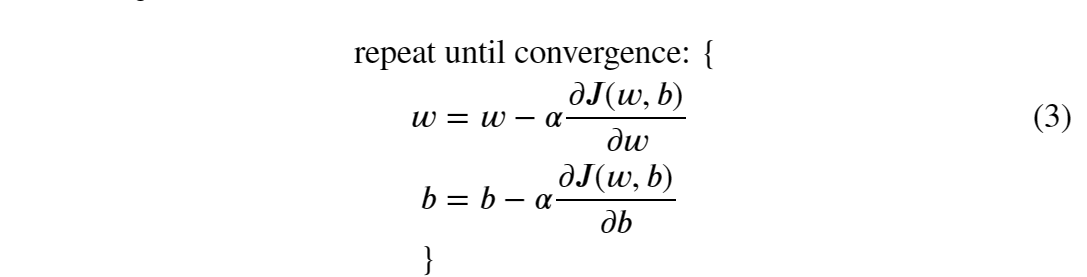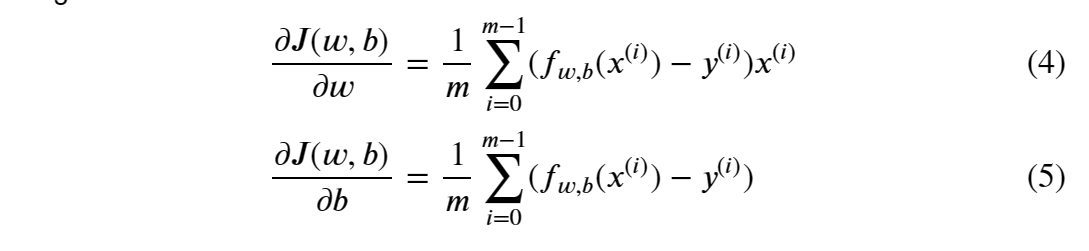defcompute_gradient(x, y, w, b): """ Computes the gradient for linear regression Args: x (ndarray (m,)): Data, m examples y (ndarray (m,)): target values w,b (scalar) : model parameters Returns dj_dw (scalar): The gradient of the cost w.r.t. the parameters w dj_db (scalar): The gradient of the cost w.r.t. the parameter b """
#Number of training examples m = x.shape[0] dj_de = 0 dj_db = 0
for i inrange(m): f_wb = w * x[i] + b; dj_dw_i = (f_wb - y[i]) * x[i] dj_db_i = f_wb - y[i] dj_db += dj_db_i dj_dw += dj_dw_i dj_dw = dj_dw / m dj_db = dj_db / m
defgradient_descent(x, y, w_in, b_in, alpha, num_iters, cost_function, gradient_function): """ Performs gradient descent to fit w,b. Updates w,b by taking num_iters gradient steps with learning rate alpha Args: x (ndarray (m,)) : Data, m examples y (ndarray (m,)) : target values w_in,b_in (scalar): initial values of model parameters alpha (float): Learning rate num_iters (int): number of iterations to run gradient descent cost_function: function to call to produce cost gradient_function: function to call to produce gradient Returns: w (scalar): Updated value of parameter after running gradient descent b (scalar): Updated value of parameter after running gradient descent J_history (List): History of cost values p_history (list): History of parameters [w,b] """
w = copy.deepcopy(w_in) # avoid modifying global w_in # An array to store cost J and w's at each iteration primarily for graphing later J_history = [] p_history = [] b = b_in w = w_in
for i inrange(num_iters): # Calculate the gradient and update the parameters using gradient_function dj_dw, dj_db = gradient_function(x, y, w , b)
# Update Parameters using equation (3) above b = b - alpha * dj_db w = w - alpha * dj_dw
# Save cost J at each iteration if i<100000: # prevent resource exhaustion J_history.append( cost_function(x, y, w , b)) p_history.append([w,b]) # Print cost every at intervals 10 times or as many iterations if < 10 if i% math.ceil(num_iters/10) == 0: print(f"Iteration {i:4}: Cost {J_history[-1]:0.2e} ", f"dj_dw: {dj_dw: 0.3e}, dj_db: {dj_db: 0.3e} ", f"w: {w: 0.3e}, b:{b: 0.5e}")
return w, b, J_history, p_history #return w and J,w history for graphing