CUDA内存管理
1.内存管理
CUDA编程模型假设系统是由一个主机和一个设备组成的,而且各自拥有独立的内存。核函数是在设备上运行的。为使你拥有充分的控制权并使系统达到最佳性能,CUDA运行时负责分配与释放设备内存,并且在主机内存和设备内存之间传输数据。表2-1列出了标准的C函数以及相应地针对内存操作的CUDA C函数。
用于执行GPU内存分配的是cudaMalloc函数,其函数原型为:
1 | |

该函数负责向设备分配一定字节的线性内存,并以devPtr的形式返回指向所分配内存的指针。cudaMalloc与标准C语言中的malloc函数几乎一样,只是此函数在GPU的内存里分配内存。通过充分保持与标准C语言运行库中的接口一致性,可以实现CUDA应用程序的轻松接入。
cudaMemcpy函数负责主机和设备之间的数据传输,其函数原型为:
1 | |
此函数从src指向的源存储区复制一定数量的字节到dst指向的目标存储区。复制方向由kind指定,其中的kind有以下几种。
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
这个函数以同步方式执行,因为在cudaMemcpy函数返回以及传输操作完成之前主机应用程序是阻塞的。除了内核启动之外的CUDA调用都会返回一个错误的枚举类型cudaError_t。如果GPU内存分配成功,函数返回:
1 | |
否则返回:
1 | |
可以使用以下CUDA运行时函数将错误代码转化为可读的错误消息:
1 | |
cudaGetErrorString函数和C语言中的strerror函数类似。
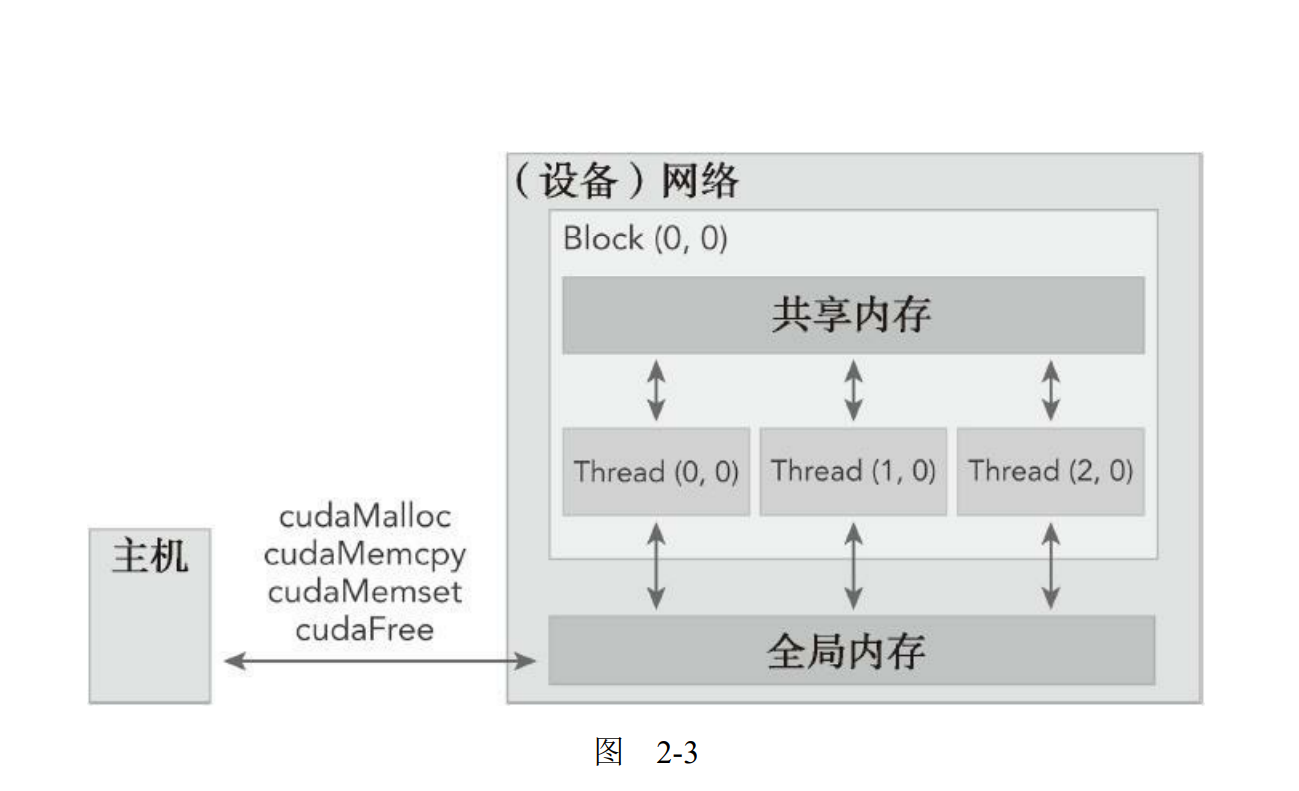
CUDA编程模型从GPU架构中抽象出一个内存层次结构,图2-3所示的是一个简化的GPU内存结构,它主要包含两部分:全局内存和共享内存。
2.内存层次结构
CUDA编程模型最显著的一个特点就是揭示了内存层次结构。每一个GPU设备都有用于不同用途的存储类型。
在GPU内存层次结构中,最主要的两种内存是全局内存和共享内存。全局类似于CPU的系统内存,而共享内存类似于CPU的缓存。然而GPU的共享内存可以由CUDA C的内核直接控制。
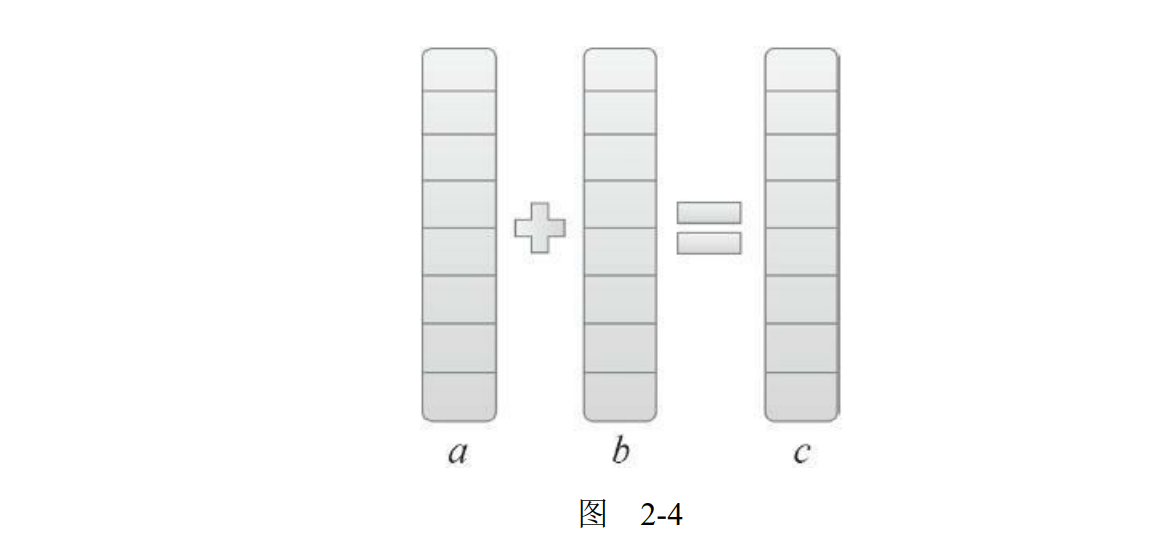
下面,我们将通过一个简单的两个数组相加的例子来学习如何在主机和设备之间进行数据传输,以及如何使用CUDA C编程。如图2-4所示,数组a的第一个元素与数组b的第一个元素相加,得到的结果作为数组c的第一个元素,重复这个过程直到数组中的所有元素都进行了一次运算。‘
首先,执行主机端代码使两个数组相加(如代码清单2-1所示)。
代码清单2-1 sumArraysOnHost.c
1 | |
这是一个纯C语言编写的程序,你可以用C语言编译器进行编译,也可以像下面这样用nvcc进行编译。
1 | |
nvcc封装了几种内部编译工具,CUDA编译器允许通过命令行选项在不同阶段启动不同的工具完成编译工作。-Xcompiler用于指定命令行选项是指向C编译器还是预处理器。在前面的例子中,将-std=c99传递给编译器,因为这里的C程序是按照C99标准编写的。
现在,你可以在GPU上修改代码来进行数组加法运算,用cudaMalloc在GPU上申请内存。
1 | |
使用cudaMemcpy函数把数据从主机内存拷贝到GPU的全局内存中,参考cudaMemcpyHostToDevice指定数据拷贝方向。
1 | |
当数据被转移到GPU的全局内存后,主机端调用核函数在GPU上进行数组求和。一旦内核被调用,控制权立刻被传回主机,这样的话,当核函数在GPU上运行时,主机可以执行其他函数。因此,内核与主机是异步的。
当内核在GPU上完成了对所有数组元素的处理后,其结果将以数组d_C的形式存储在GPU的全局内存中,然后用cudaMemcpy函数把结果从GPU复制回到主机的数组gpuRef中。
1 | |
cudaMemcpy的调用会导致主机运行阻塞。cudaMemcpyDeviceToHost的作用就是将存储在GPU上的数组d_C中的结果复制到gpuRef中。最后,调用cudaFree释放GPU的内存。
1 | |
3.不同的存储空间
使用CUDA C进行编程的人最常犯的错误就是对不同内存空间的不恰当引用。对于在GPU上被分配的内存来说,设备指针在主机代码中可能并没有被引用。如果你执行了错误的内存分配,如:
1 | |
而不是用:
1 | |
应用程序在运行时将会崩溃。
为了避免这类错误,CUDA6.0提出了统一寻址,使用一个指针来访问CPU和GPU的内存
4.参考资料
CUDA C编程权威指南 程润伟,Max Grossman(美),Ty Mckercher
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!