CUDA线程管理
1.线程管理
当核函数在主机端启动时,它的执行会移动到设备上,此时设备中会产生大量的线程并且每个线程都执行由核函数指定的语句。了解如何组织线程是CUDA编程的一个关键部分。CUDA明确了线程层次抽象的概念以便于你组织线程。这是一个两层的线程层次结构,由线程块和线程块网格构成,如图2-5所示。
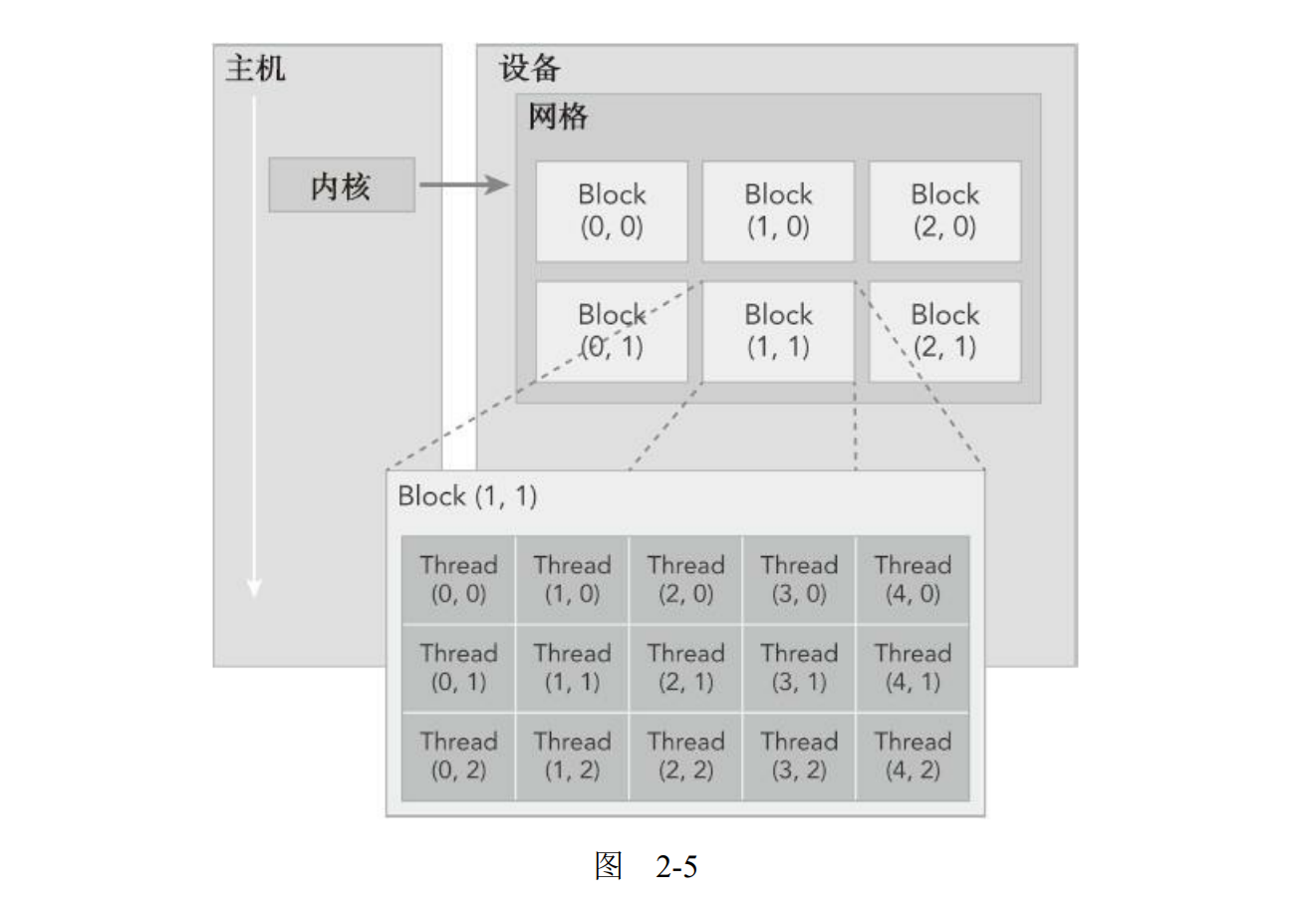
由一个内核启动所产生的所有线程统称为一个网格。同一网格中的所有线程共享相同的全局内存空间。一个网格由多个线程块构成,一个线程块包含一组线程,同一线程块内的线程协作可以通过以下方式来实现。
-同步
-共享内存
不同块内的线程不能协作。
线程依靠以下两个坐标变量来区分彼此。
-blockIdx(线程块在线程格内的索引)
-threadIdx(块内的线程索引)
这些变量是核函数中需要预初始化的内置变量。当执行一个核函数时,CUDA运行时为每个线程分配坐标变量blockIdx和threadIdx。基于这些坐标,你可以将部分数据分配给不同的线程。
该坐标变量是基于uint3定义的CUDA内置的向量类型,是一个包含3个无符号整数的结构,可以通过x,y,z三个字段来指定。
1 | |
CUDA可以组织三维的网格和块。图2-5展示了一个线程层次结构的示例,其结构是一个包含二维块的二维网格。网格和块的维度由下列两个内置变量指定。
-blockDim(线程块的维度,用每个线程块中的线程数来表示)
-gridDim(线程格的维度,用每个线程格中的线程数来表示)
它们是dim3类型的变量,是基于uint3定义的整数型向量,用来表示维度。当定义一个dim3类型的变量时,所有未指定的元素都被初始化为1。dim3类型变量中的每个组件可以通过它的x,y,z字段获得。如下所示。
1 | |
2.网格和线程块的维度
通常,一个线程格会被组织成线程块的二维数组形式,一个线程块会被组织成线程的三维数组形式。
线程格和线程块均使用3个dim3类型的无符号整型字段,而未使用的字段将被初始化为1且忽略不计。
在CUDA程序中有两组不同的网格和块变量:手动定义的dim3数据类型和预定义的uint3数据类型。在主机端,作为内核调用的一部分,你可以使用dim3数据类型定义一个网格和块的维度。当执行核函数时,CUDA运行时会生成相应的内置预初始化的网格,块和线程变量,它们在核函数内均可被访问到且为unit3类型。手动定义的dim3类型的网络和块变量仅在主机端可见,而unit3类型的内置预初始化的网格和块变量仅在设备端可见。
你可以通过代码清单2-2来验证这些变量如何使用。首先,定义程序所用的数据大小,为了对此进行说明,我们定义一个较小的数据。
1 | |
接下来,定义块的尺寸并基于块和数据的大小计算网格尺寸。在下面例子中,定义了一个包含3个线程的一维线程块,以及一个基于块和数据大小定义的一定数量线程块的一维线程网格。
1 | |
你会发现网格大小是块大小的倍数。以下主机端上的程序段用来检查网格和块维度。
1 | |
在核函数中,每个线程都输出自己的线程索引,块索引,块维度和网格维度。
1 | |
把代码合并保存成名为checkDimension.cu的文件,如代码清单2-2所示。
代码清单2-2 检查网络和块的索引和维度(checkDimension.cu)
1 | |
现在开始编译和运行这段程序:
1 | |
因为printf函数只支持Fermi及以上版本的GPU架构,所以必须添加-arch=sm_20编译器选项。默认情况下,nvcc会产生支持最低版本GPU架构的代码。这个应用程序的运行结果如下。可以看到,每个线程都有自己的坐标,所有的线程都有相同的块维度和网格维度。

3.从主机端和设备端访问网格/块变量
区别主机端和设备端的网格和块变量的访问是很重要的。例如,声明一个主机端的块变量,你按如下定义它的坐标并对其进行访问:
1 | |
在设备端,你已经预定义了内置块变量的大小:
1 | |
总之,在启动内核之前就定义了主机端的网格和块变量,并从主机端通过由x,y,z三个字段决定的矢量结构来访问它们。当内核启动时,可以使用内核中预初始化的内置变量。
对于一个给定的数据大小,确定网格和块尺寸的一般步骤为:
-确定块的大小
-在已知数据大小和块大小的基础上计算网格维度
要确定块尺寸,通常需要考虑:
-内核的性能特性
-GPU资源的限制
代码清单2-3使用了一个一维网格和一个一维块来说明当块的大小改变时,网格的尺寸也会随之改变。
代码清单2-3 在主机上定义网格和块的大小(defineGridBlock.cu)
1 | |
用下列命令编译和运行这段程序:
1 | |
下面是一个输出示例。由于应用程序中的数据大小是固定的,因此当块的大小发生改变时,相应的网格尺寸也会发生改变。

4.线程层次结构
CUDA的特点之一就是通过编程模型揭示了一个两层的线程层次结构。由于一个内核启动的网格和块的维数会影响性能,这一结构为程序员优化程序提供了一个额外的途径。
网格和块的维度存在几个限制因素,对于块大小的一个主要限制因素就是可利用的计算资源,如寄存器,共享内存等。某些限制可以通过查询GPU设备撤回。
网格和块从逻辑上代表了一个核函数的线程层次结构。
5.参考资料
CUDA C编程权威指南 程润伟,Max Grossman(美),Ty Mckercher
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!