BLISlab dgemm优化
BLISlab dgemm优化
参考资料:
Git地址:https://github.com/flame/blislab
视频教程:https://www.bilibili.com/video/BV1c94y117Uw?vd_source=3ae32e36058f58c5b85935fca9b77797【澎峰科技-张先轶老师】
阅读:tutorial.pdf【位于代码包中】
Step0
1.克隆项目到本地
1 | |
2.代码结构

3.编译环境

4.运行环境配置脚本
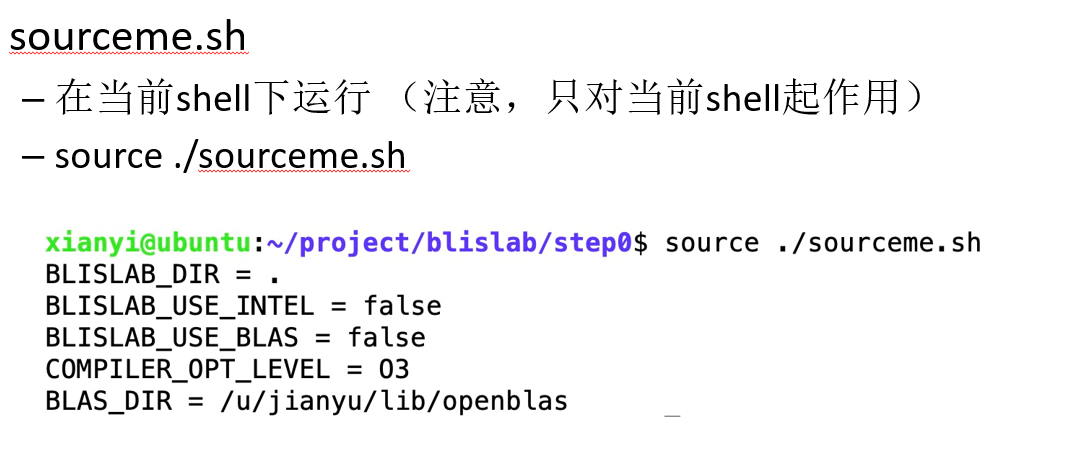
1 | |
5.Makefile

1 | |
6.make.gnu.inc

7.ref参考实现是否调用BLAS

8.my_dgemm.c

9.相关数据变量含义
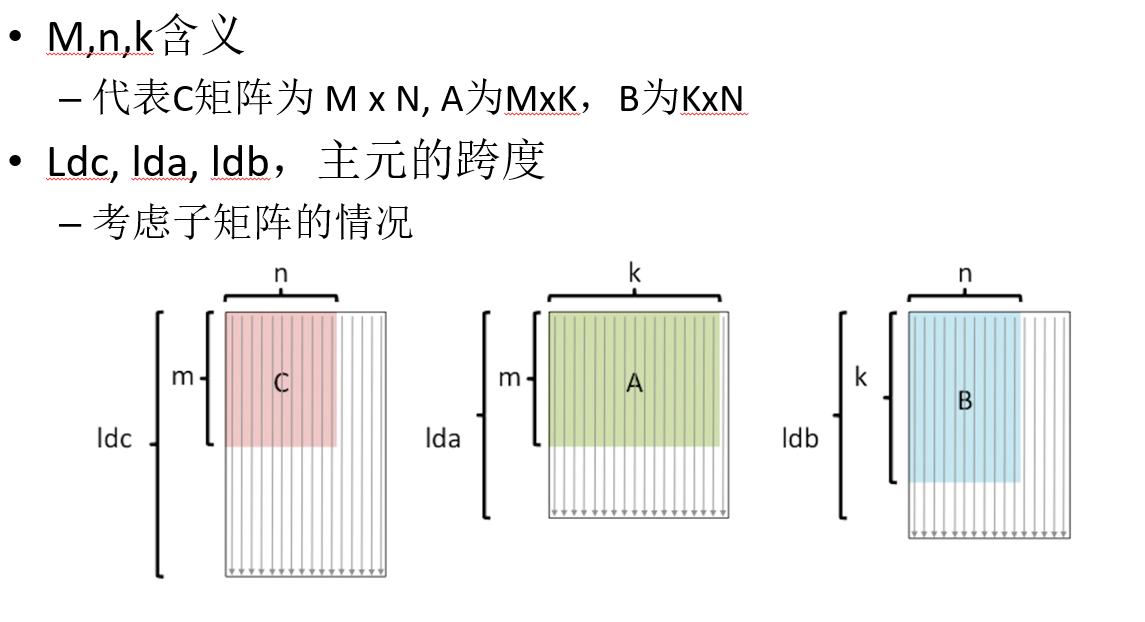
10.代码采用列主元

11.dgemm使用脚本测试
Test目录下
1 | |
1 | |
12.dgemm手动指定参数测试
Test目录下
1 | |
1 | |
这里要注意哪个代表m,n,k?
1 | |
13.计时区域
1 | |
14.正确性检验
Test目录下Test_bl_gemm.c
结果比较:通过比较你的优化计算结果和参考计算结果对比
Gflops的计算
- 有效浮点次数 = 2*m*n*k
- Gflops = 有效浮点次数 / 时间
1 | |
15.课后作业
perf工具的用法:
perf-系统级性能分析工具 - Amicoyuan (xingyuanjie.top)
分析不同的j,p,i循环顺序的性能:
原因cache miss造成的差异
Step1
1.与Step0比较
左边是Step1右边是Step0

2.基本分块
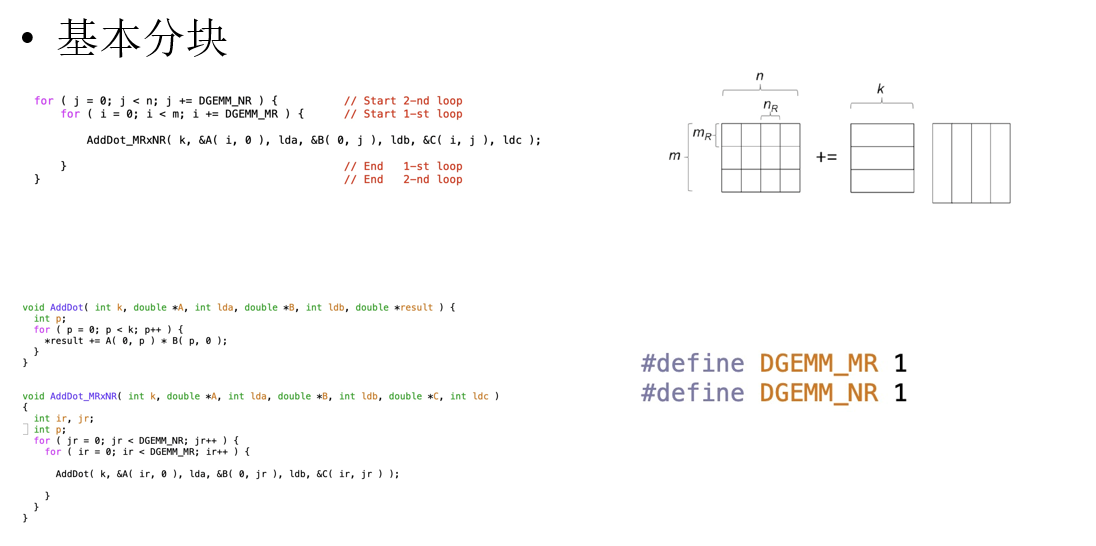
3.反汇编
1 | |
1 | |
4.反汇编(-fPIC引入的差异)
1 | |

5.Gcc生成汇编
1 | |

6.Step0与Step1比较

7.分块,修改MR, NR为4×4

8.分块(2×2)
1 | |

9.AddDot_2x2汇编代码

10.AddDot_2x2最内层循环展开
1 | |

11.AddDot_2x2汇编代码【最内层循环展开】

Step2
1.与Step1的性能比较

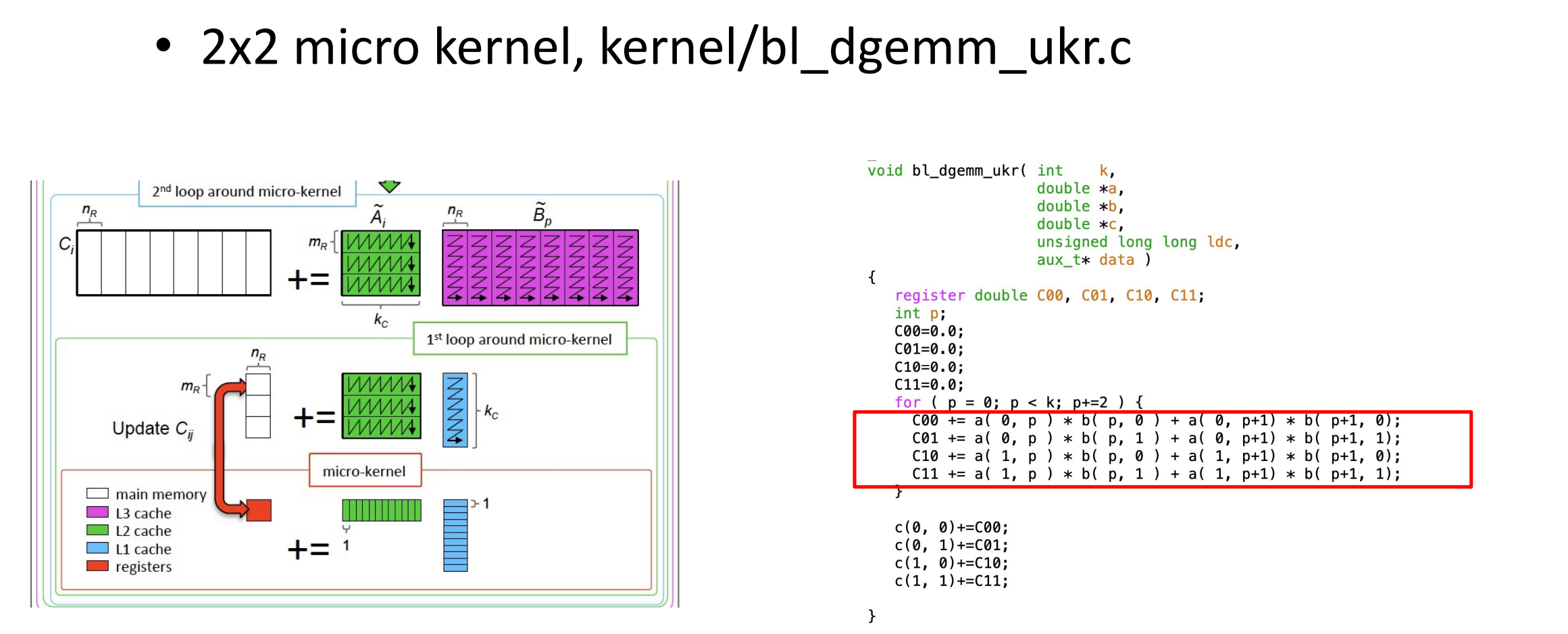
2.优化kernel/bl_dgemm_ukr.c


3.优化后性能对比
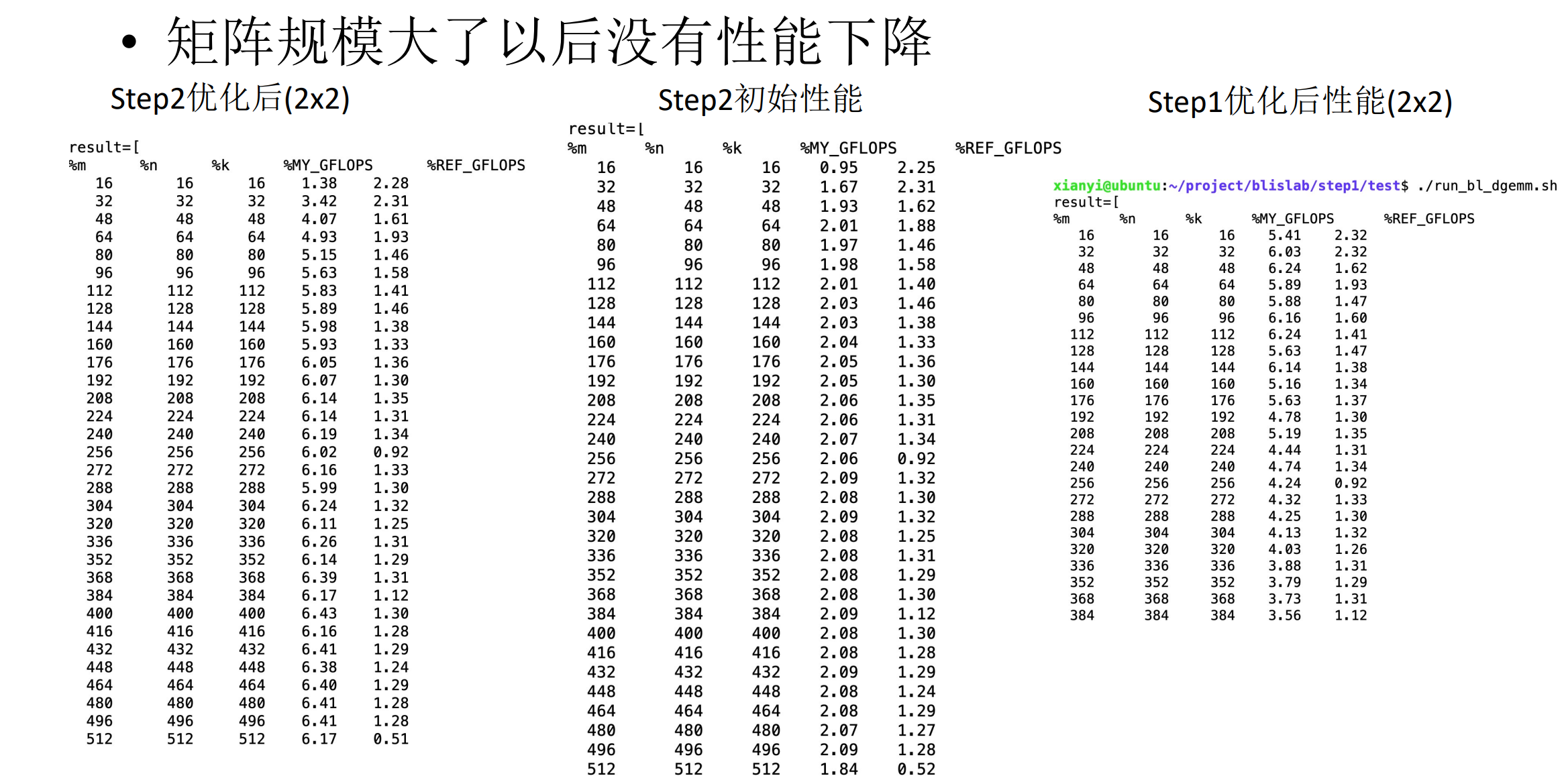
4.下降原因分析
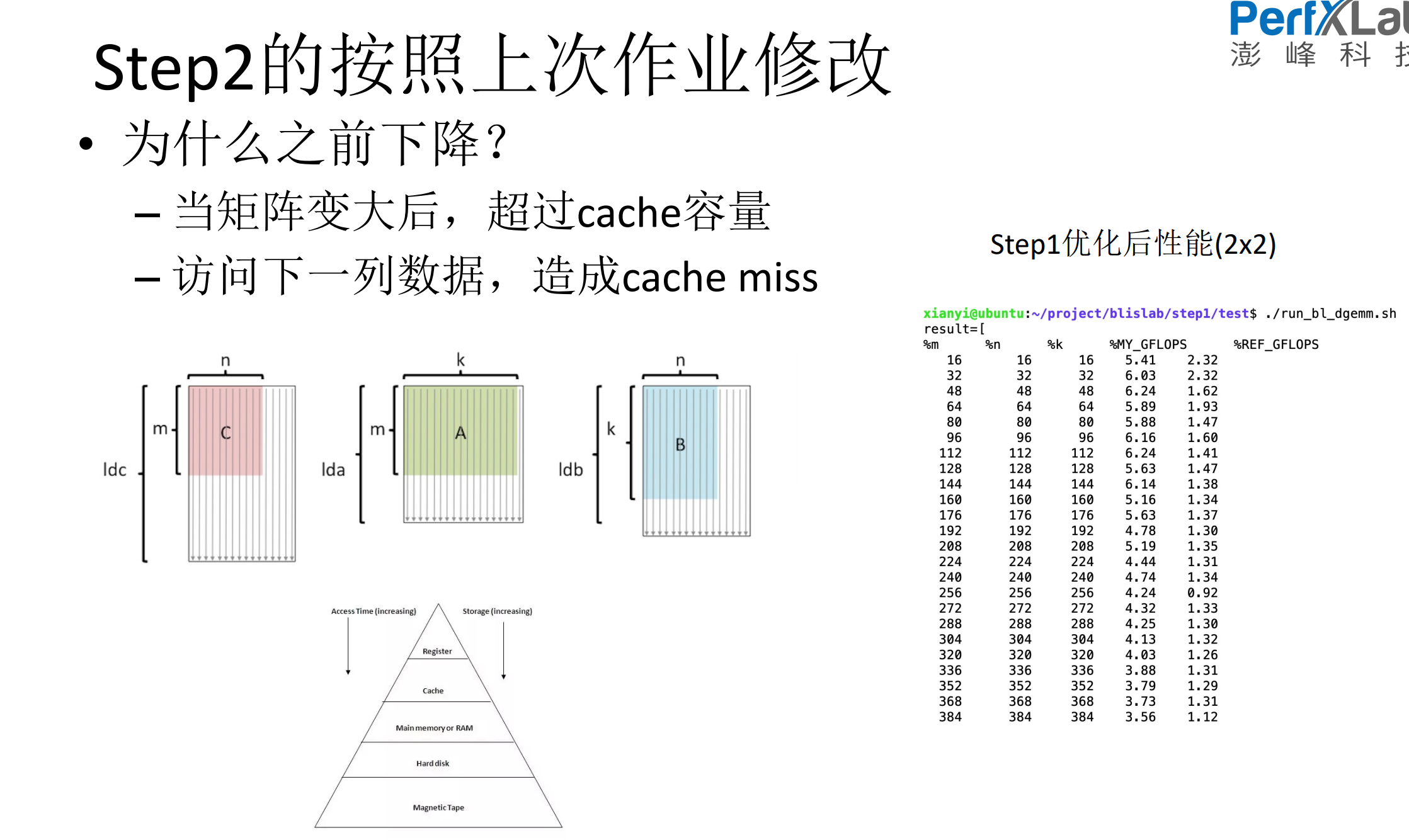

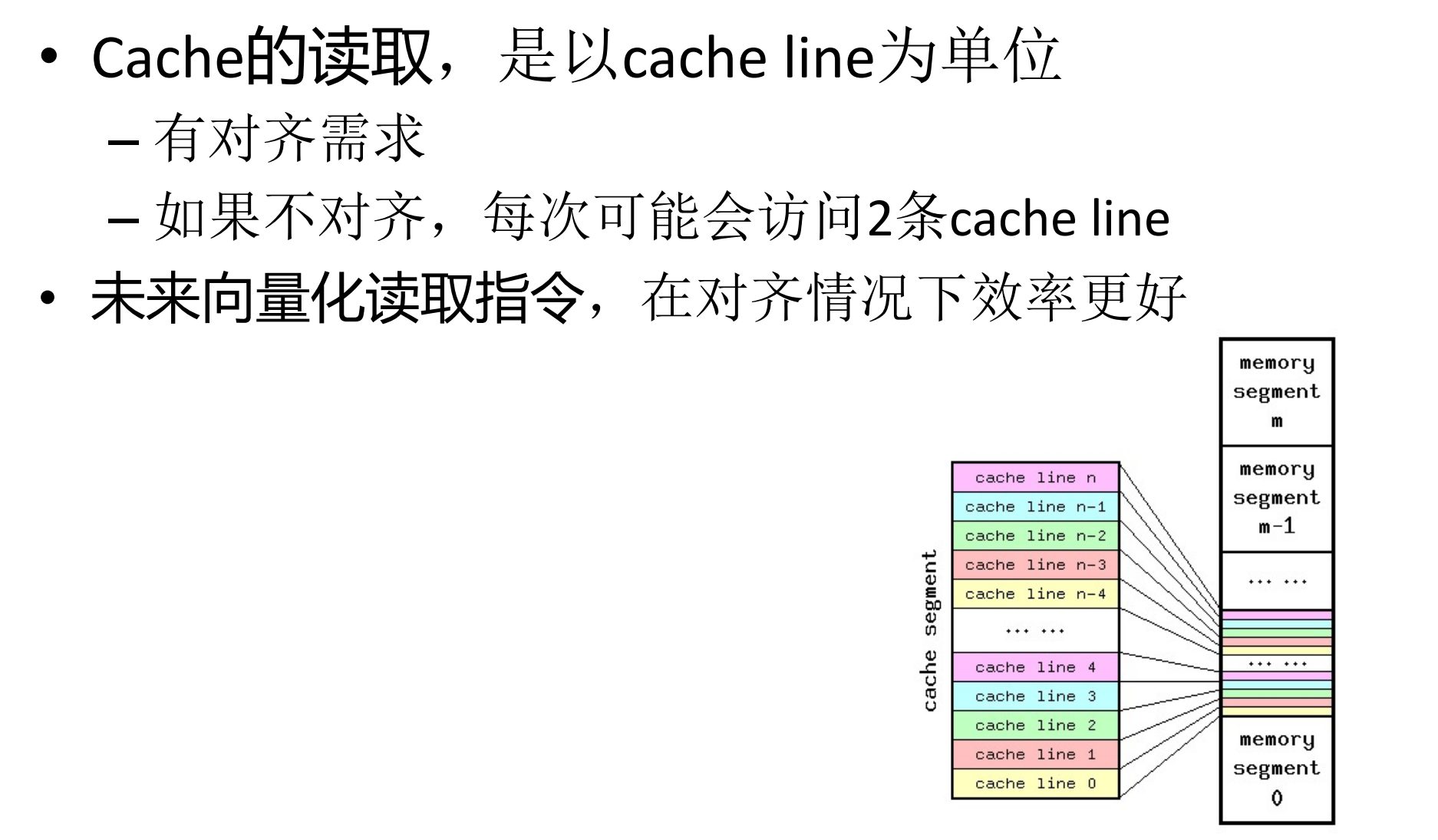
5.如何进行分块
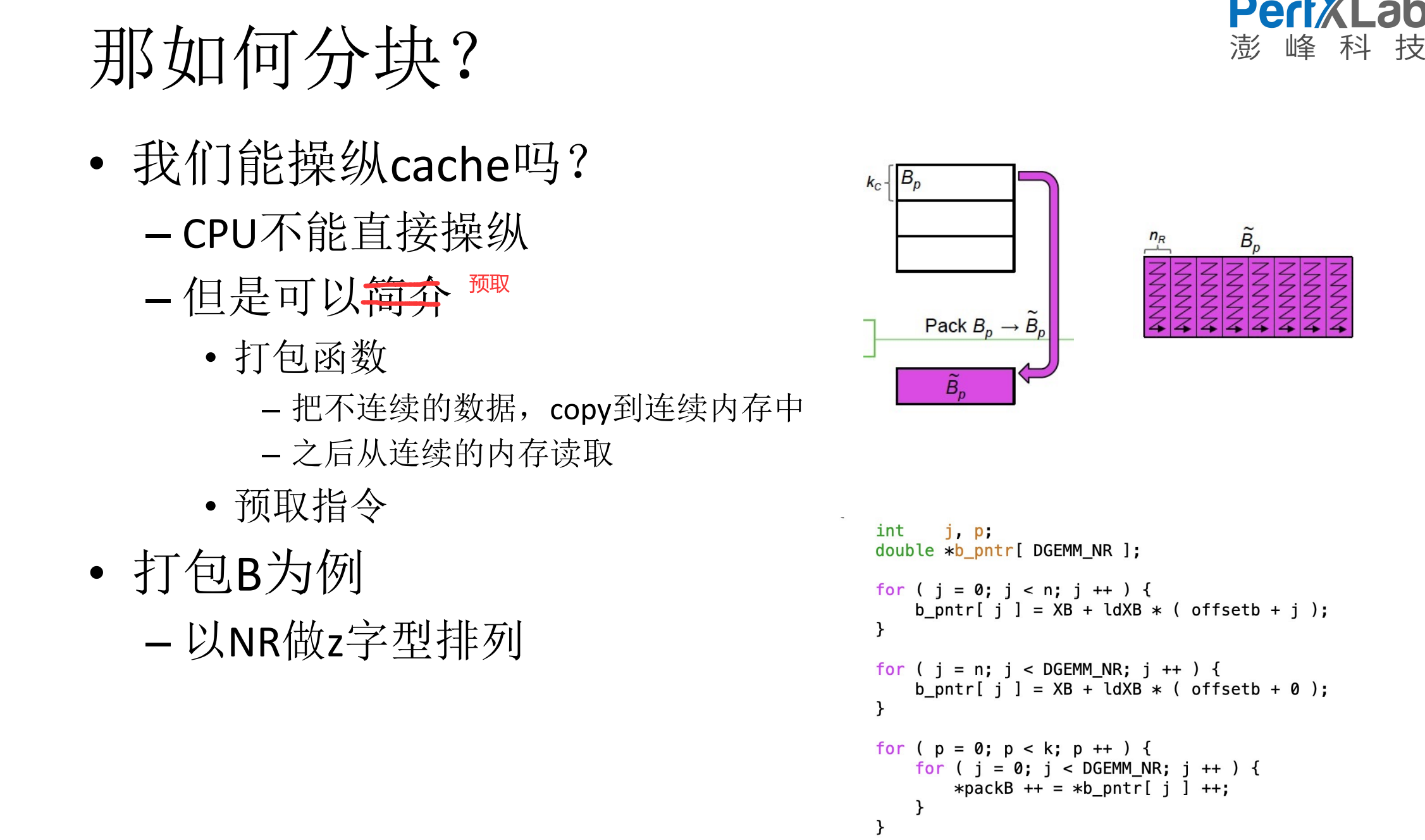

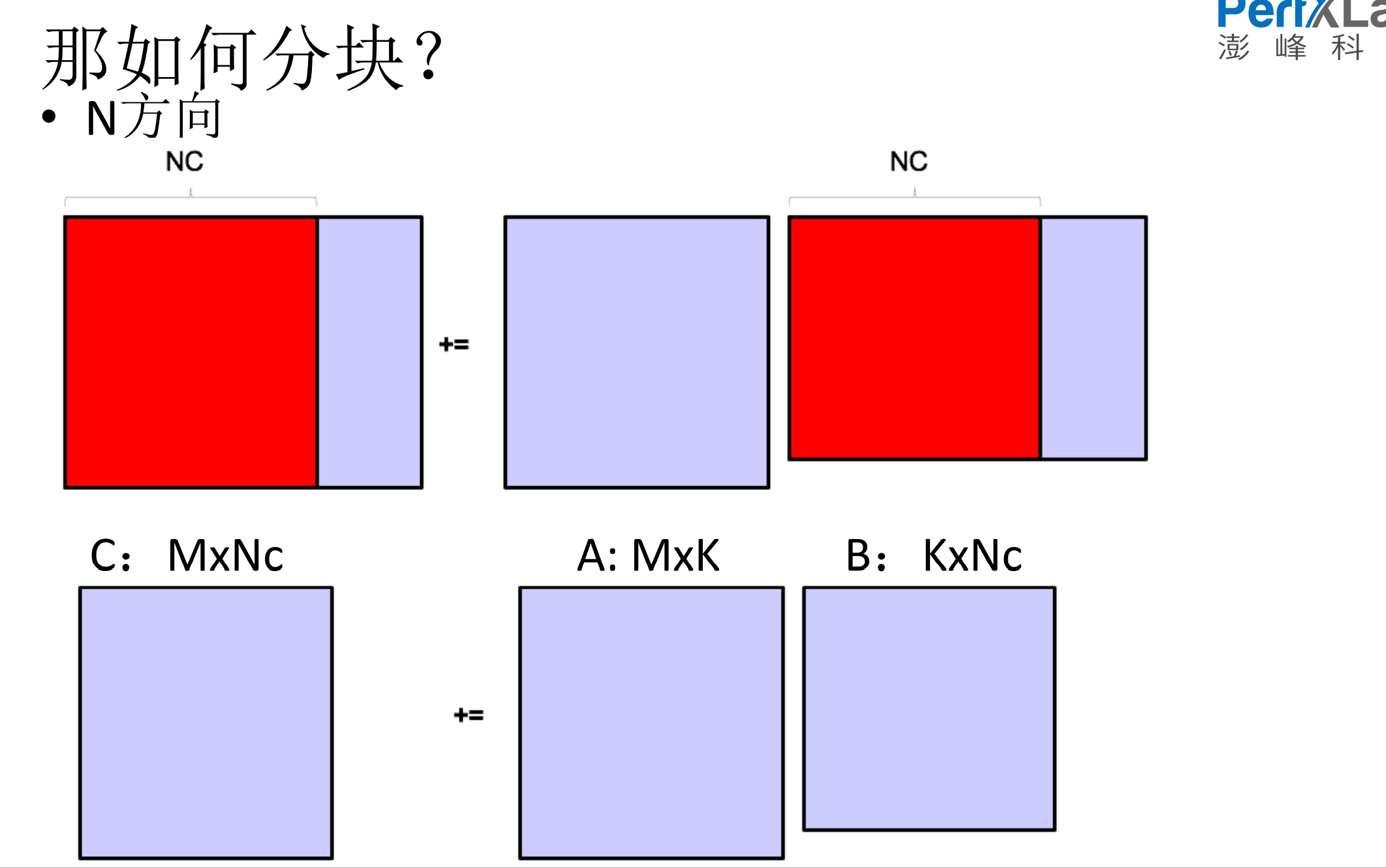
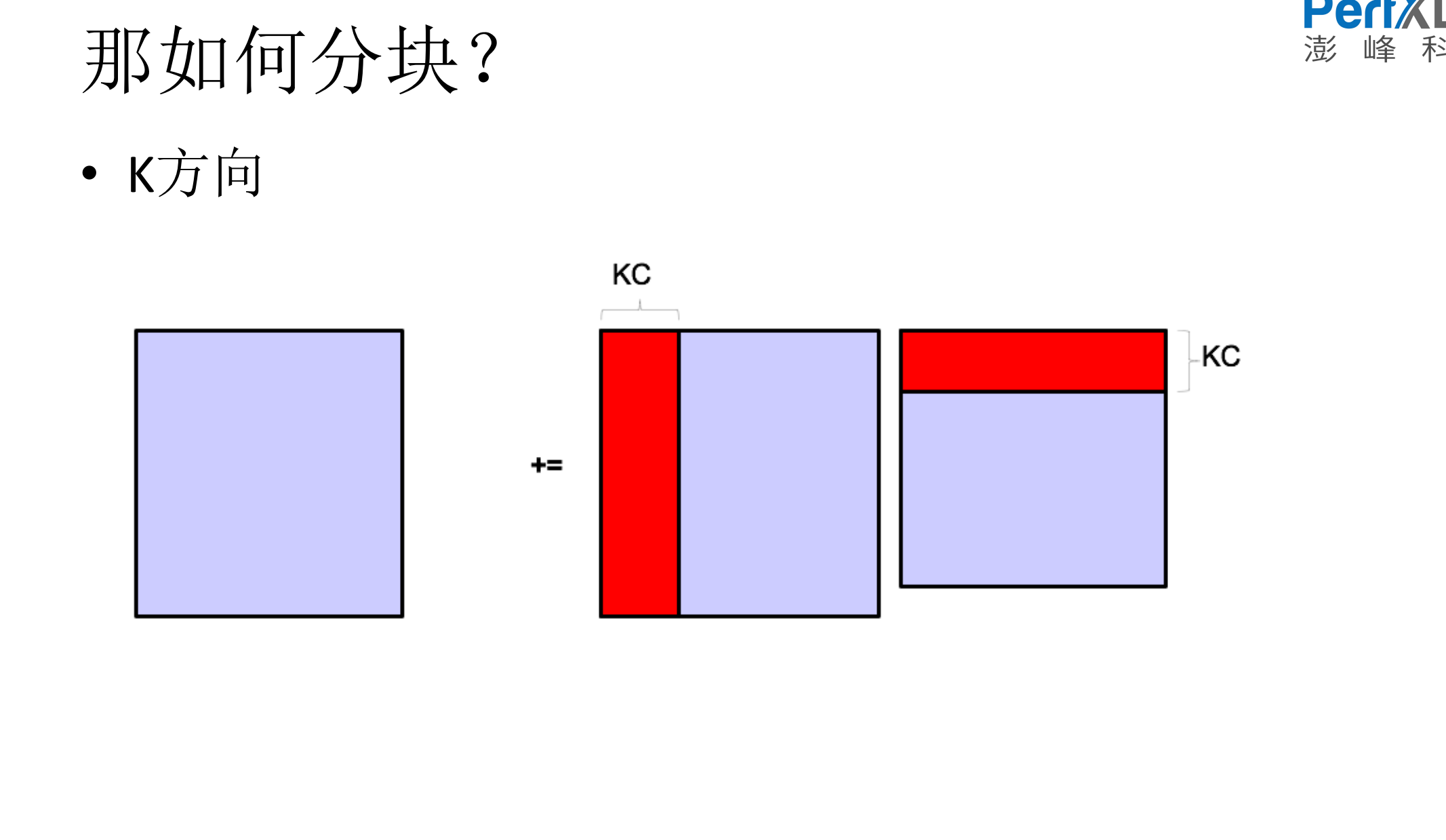
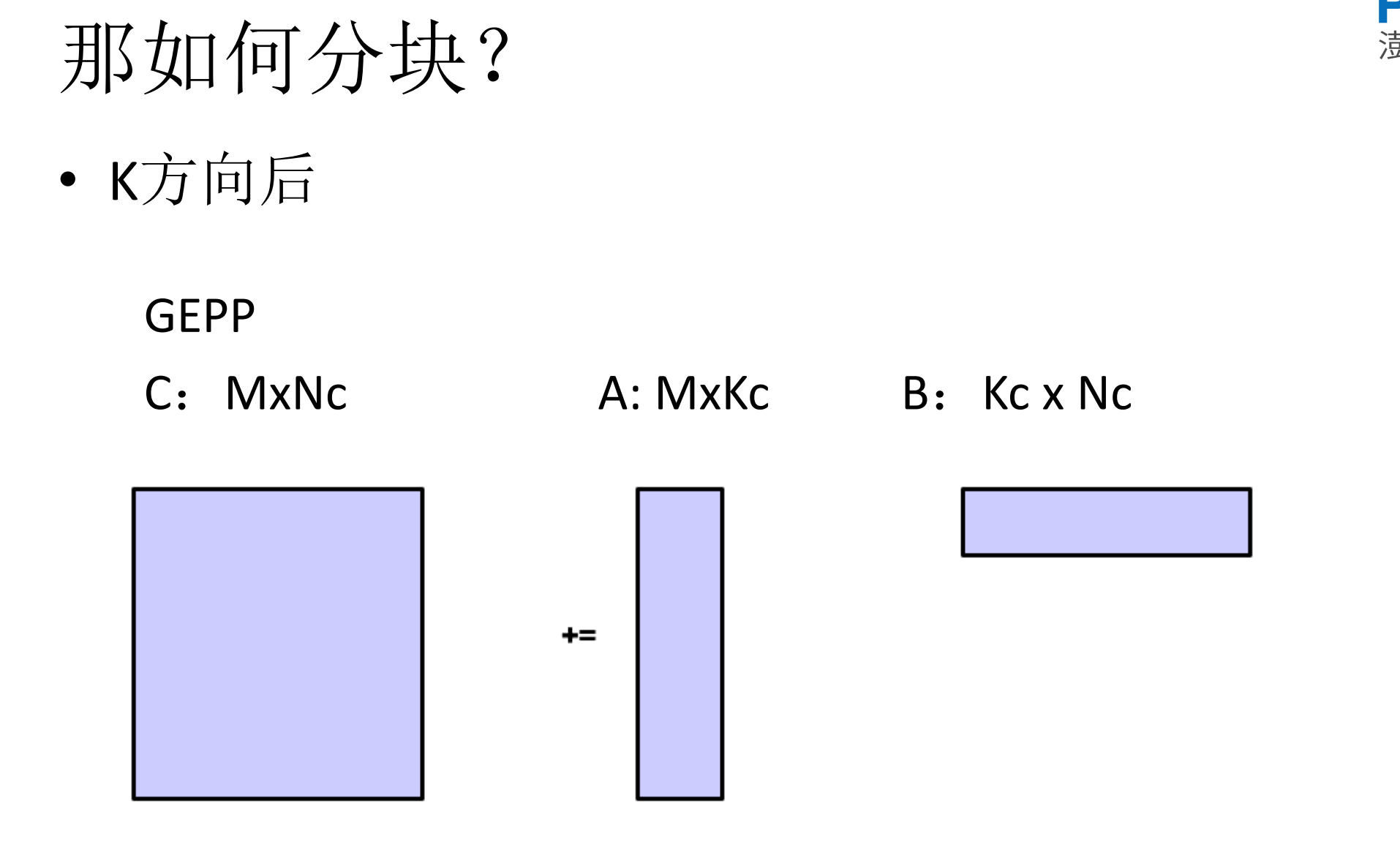
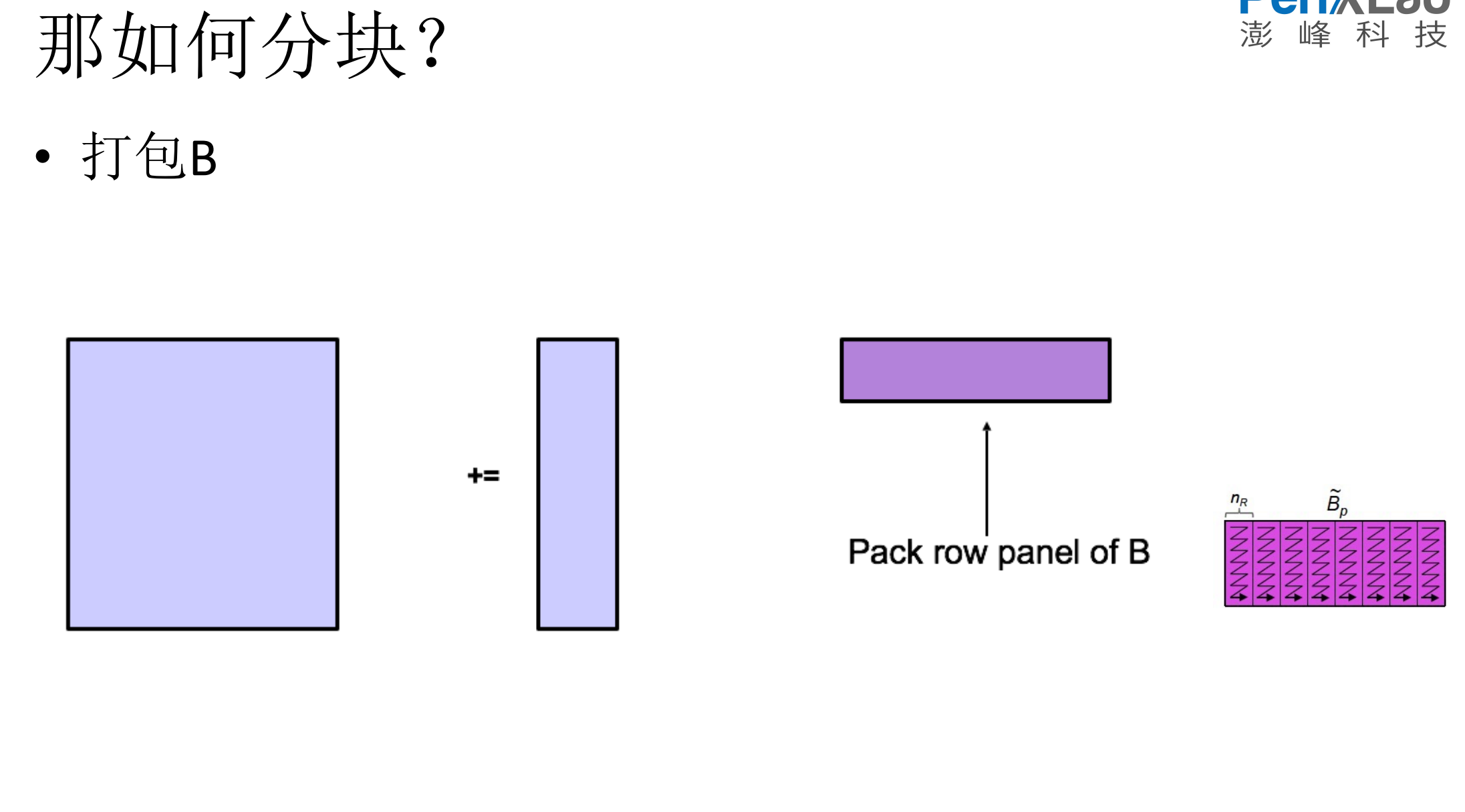
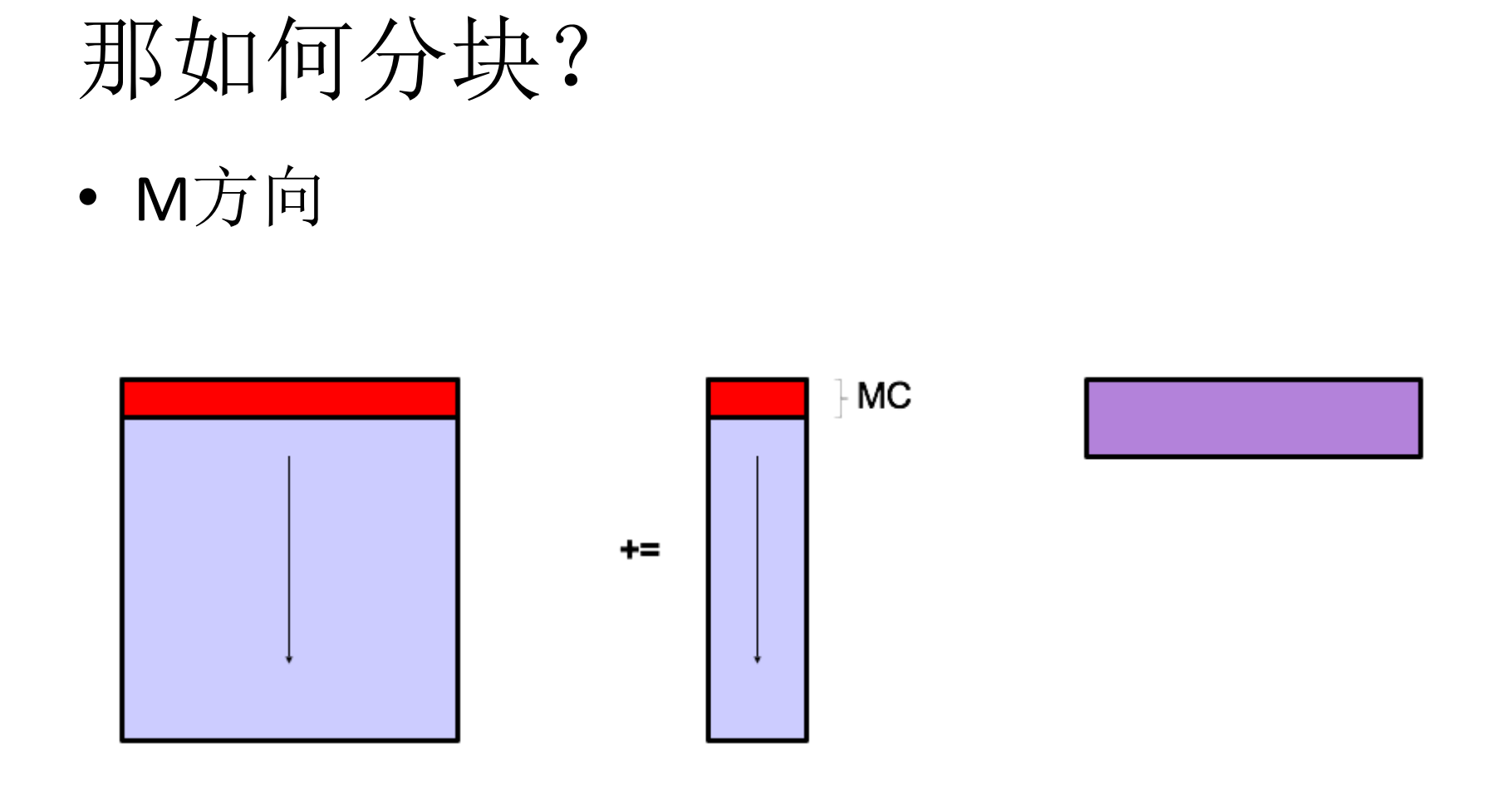
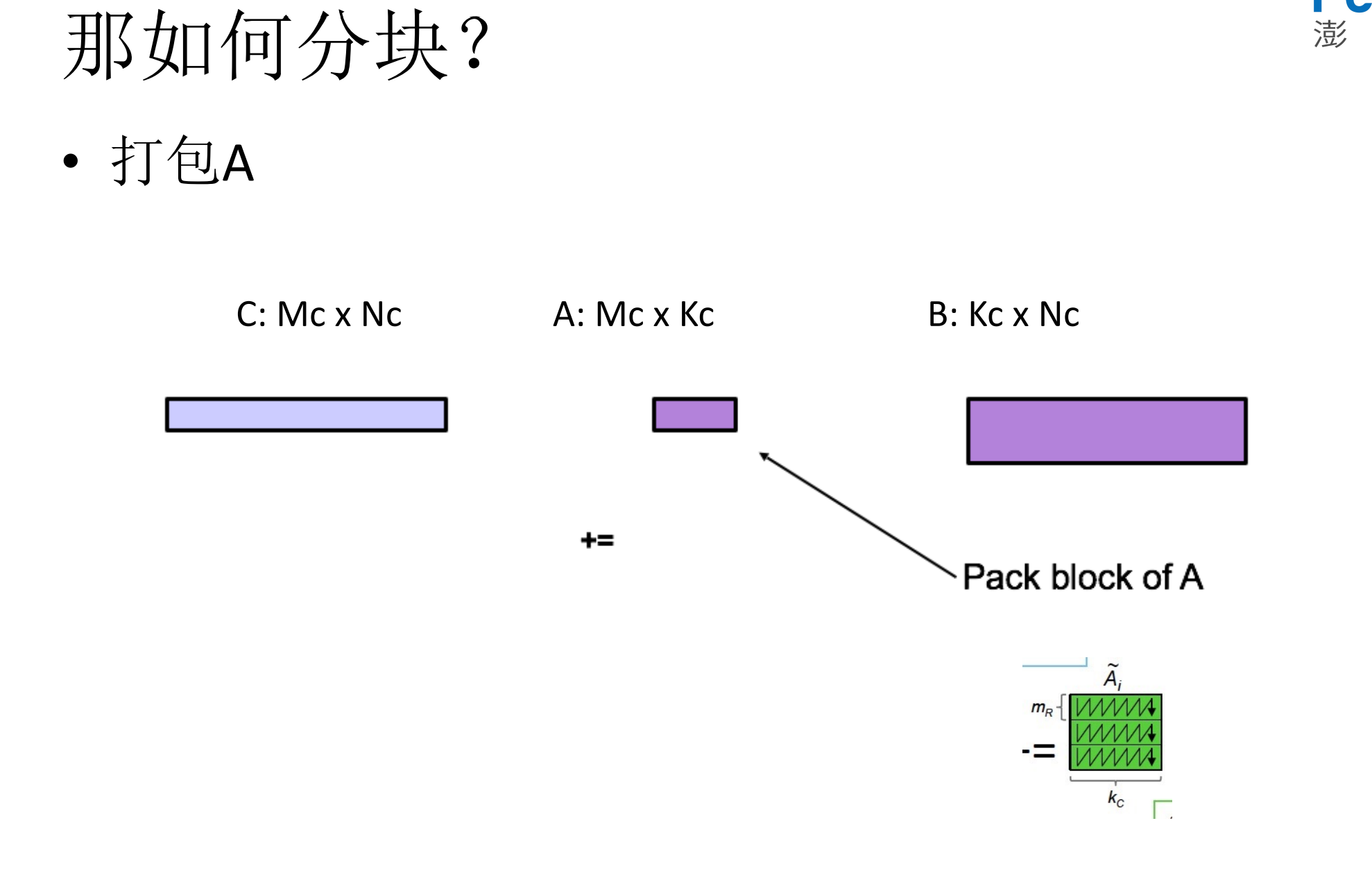
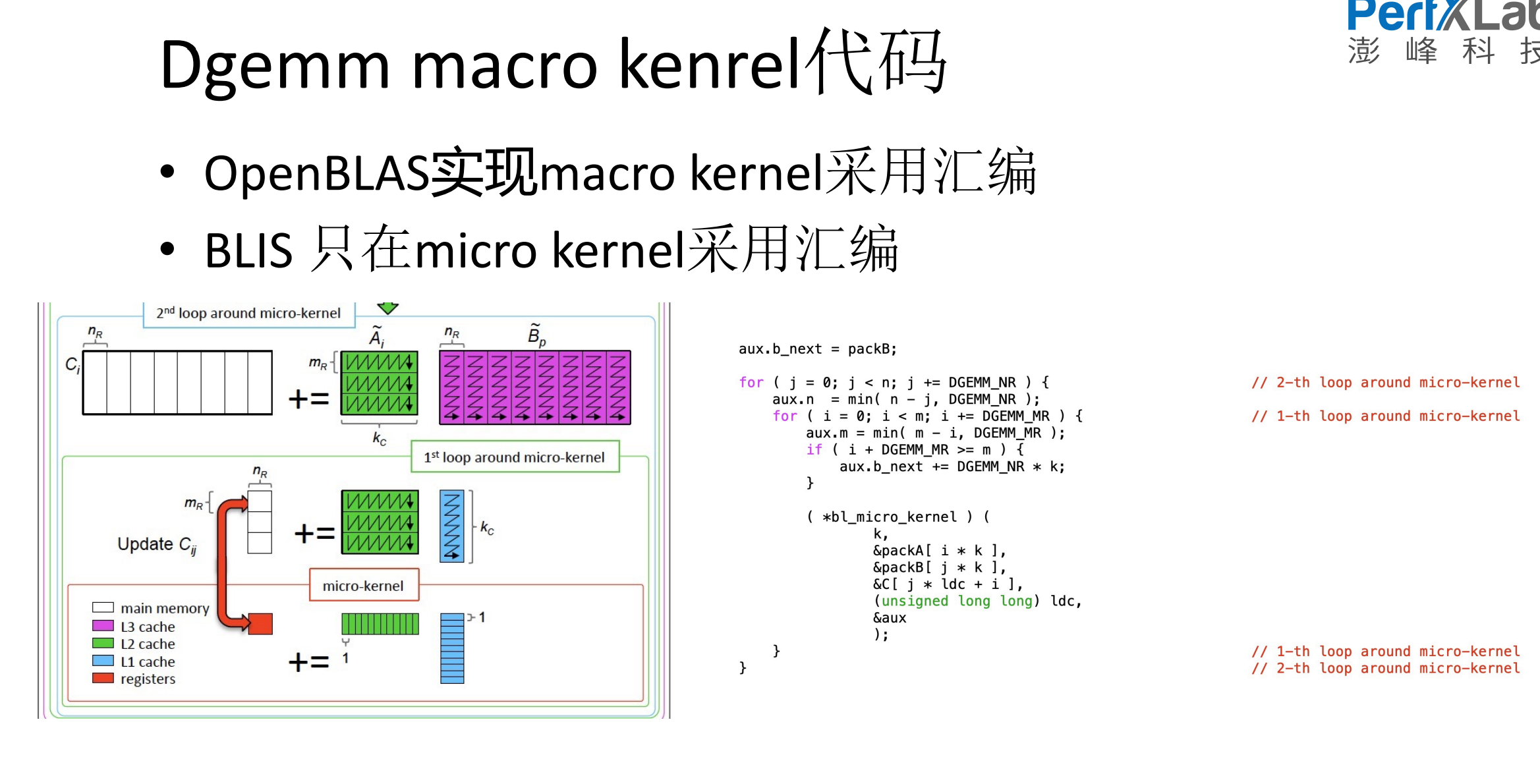
6.Dgemm代码

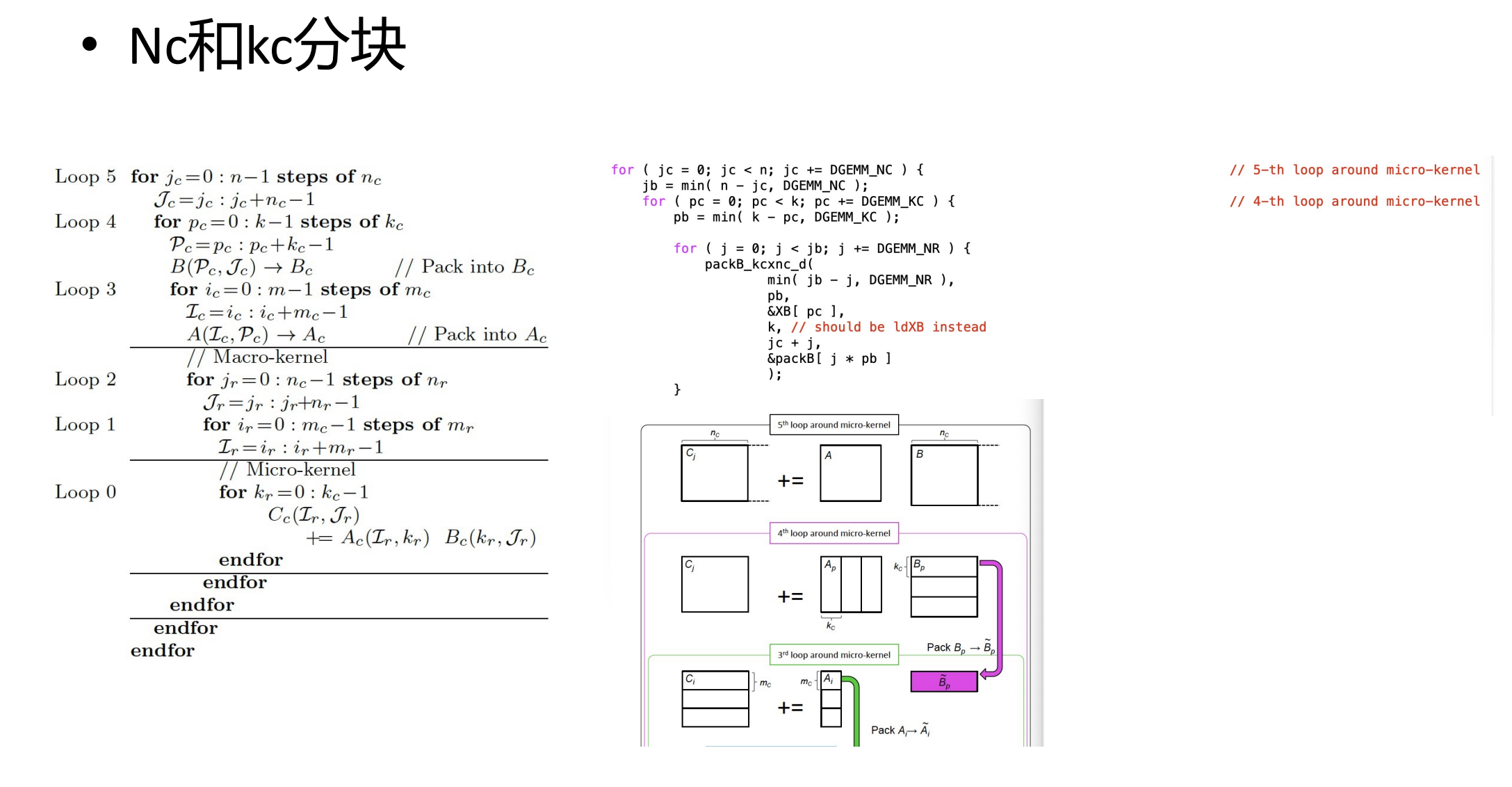

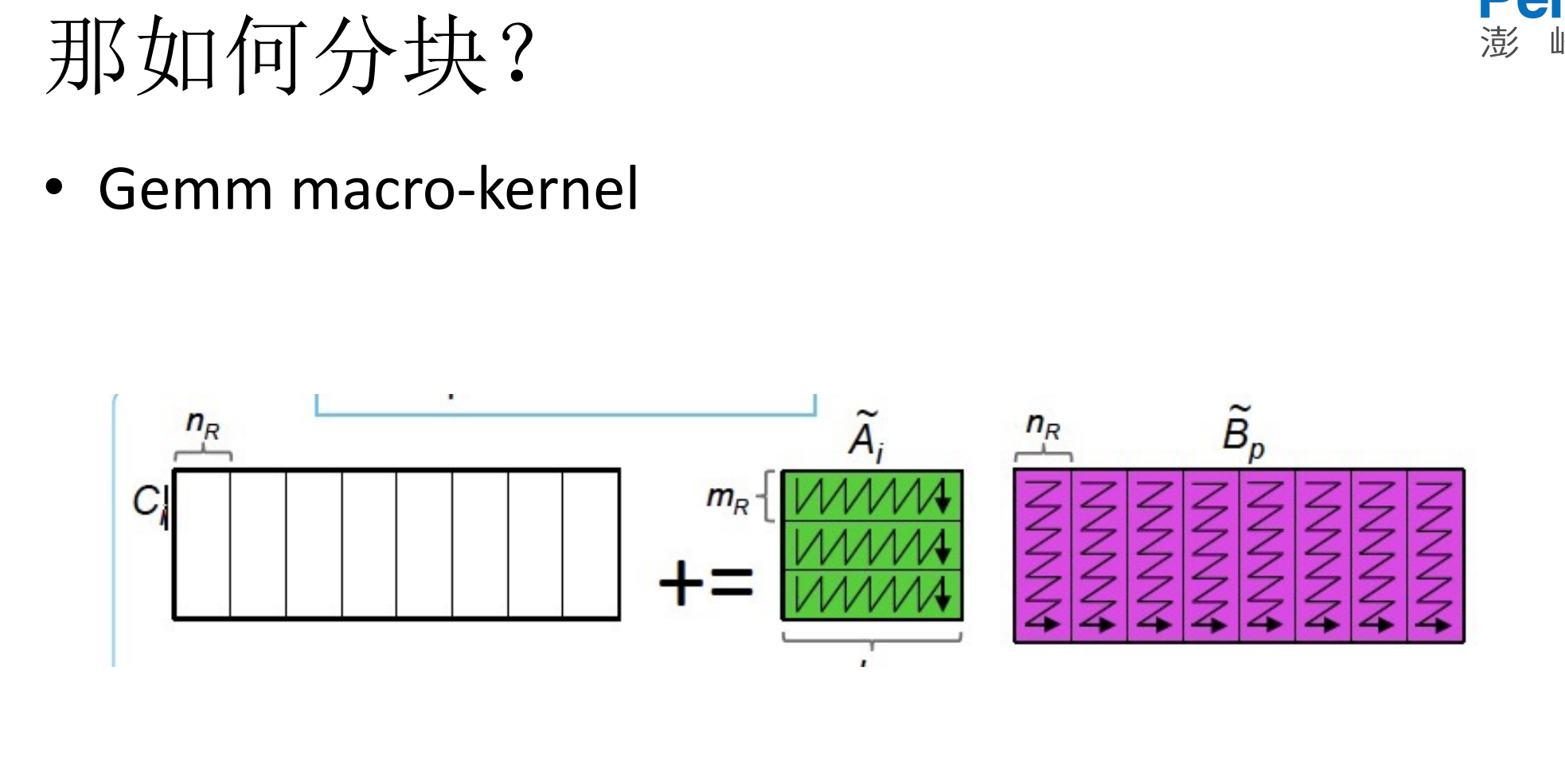
7.Dgemm macro kenrel代码
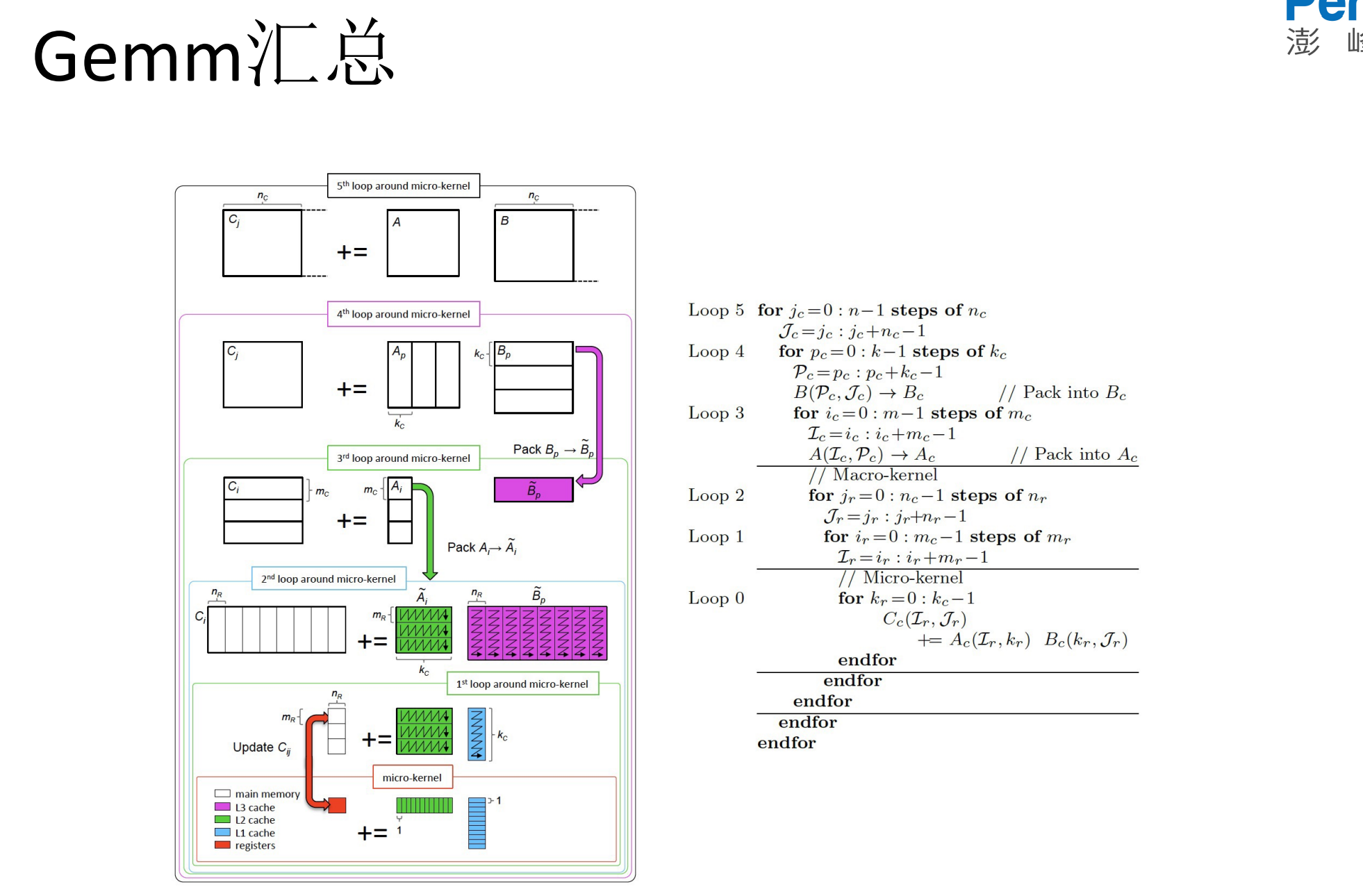
8.Gemm汇总
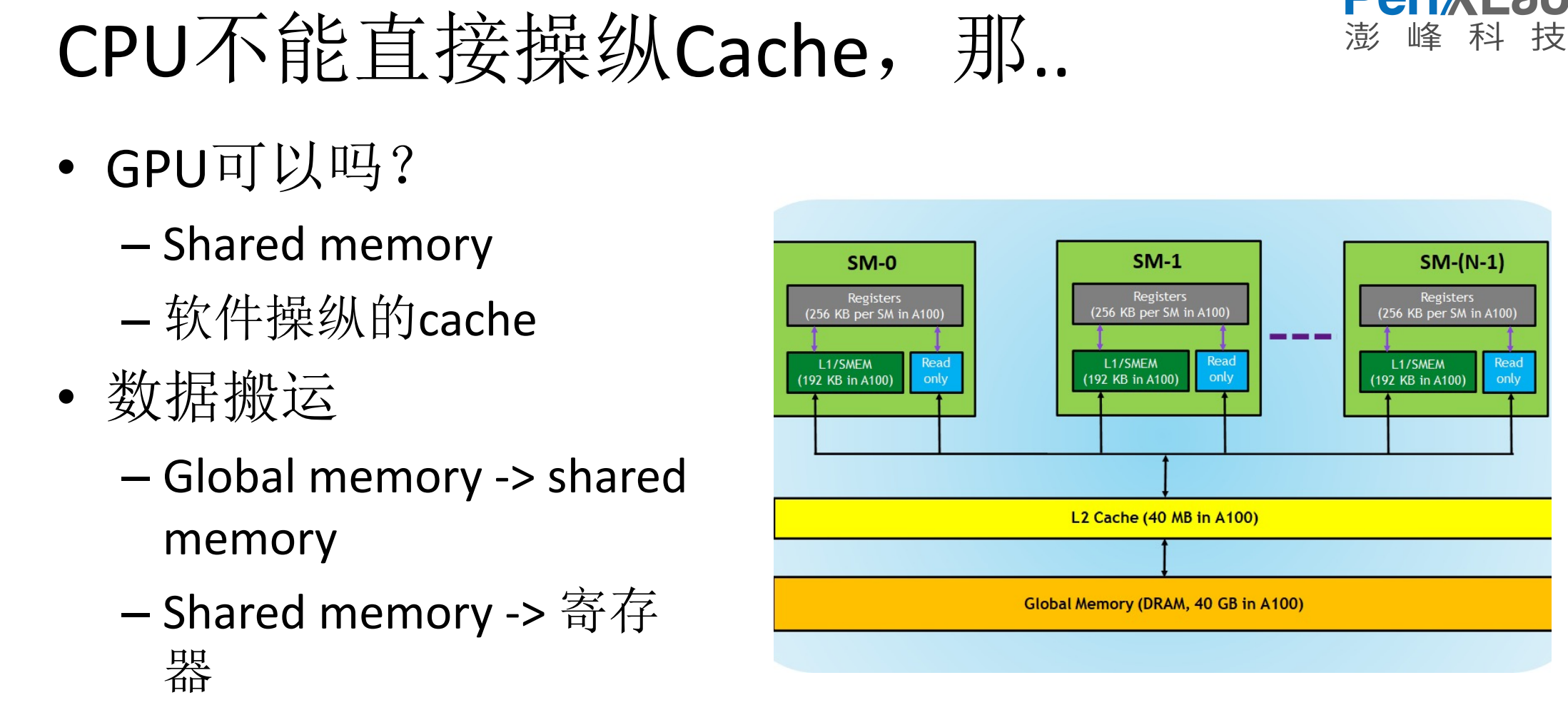
9.拓展
10.双缓冲优化

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!