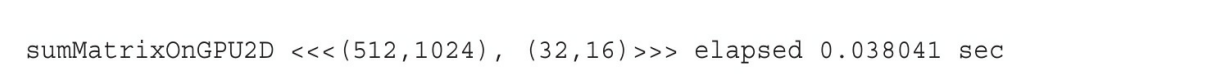int main(int argc, char **argv){
printf("%s Starting...\n",zrgv[0]);
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n",dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
int nx = 1<<14;
int ny = 1<<14;
int nxy = nx*ny;
int nBytes = nxy *sizeof(float);
printf("Matrix size: nx %d ny %d\n",nx,ny);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
double iStart = cpuSecond();
initialData (h_A, nxy);
initialData (h_B, nxy);
double iElaps = cpuSecond() - iStart;
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
iStart = cpuSecond();
sumMatrixOnHost (h_A, h_B, hostRef, nx,ny);
iElaps = cpuSecond() - iStart;
float *d_MatA, *d_MatB, *d_MatC;
cudaMalloc((void **)&d_MatA,nBytes);
cudaMalloc((void **)&d_MatB,nBytes);
cudaMalloc((void **)&d_MatC,nBytes);
cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice);
int dimx = 32;
int dimy = 32;
dim3 block(dimx,dimy);
dim3 grid((nx+block.x-1)/block.x,(ny+block.y-1)/block.y);
iStart = cpuSecond();
sumMatrixOnGPU2D<<<grid,block>>>(d_MatA, d_MatB, d_MatC, nx,ny);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
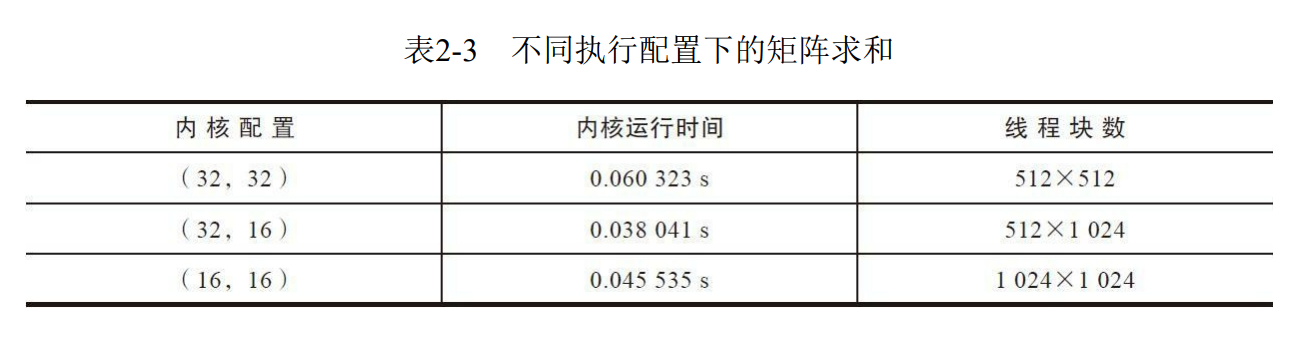
printf("sumMatrixOnGPU2D<<<(%d,%d),(%d,%d)>>> elapsed %f sec\n",grid.x, grid.y, block.x,block.y,iElaps);
cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost);
checkResult(hostRef, gpuRef,nxy);
cudaFree(d_MatA);
cudaFree(d_MatB);
cudaFree(d_MatC);
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
cudaDeviceReset();
return (0);
}