Computing four elements at a time
Computing four elements at a time
- 我们在子程序AddDot1x4中一次计算4个元素,该子程序一次执行4个内部乘积
- Optimization_1x4_3 · flame/how-to-optimize-gemm Wiki (github.com)
- 现在我们内联(inline)四个独立的内积,并将循环融合为一个,从而在一个循环中同时计算四个内积:
- Optimization_1x4_4 · flame/how-to-optimize-gemm Wiki (github.com)
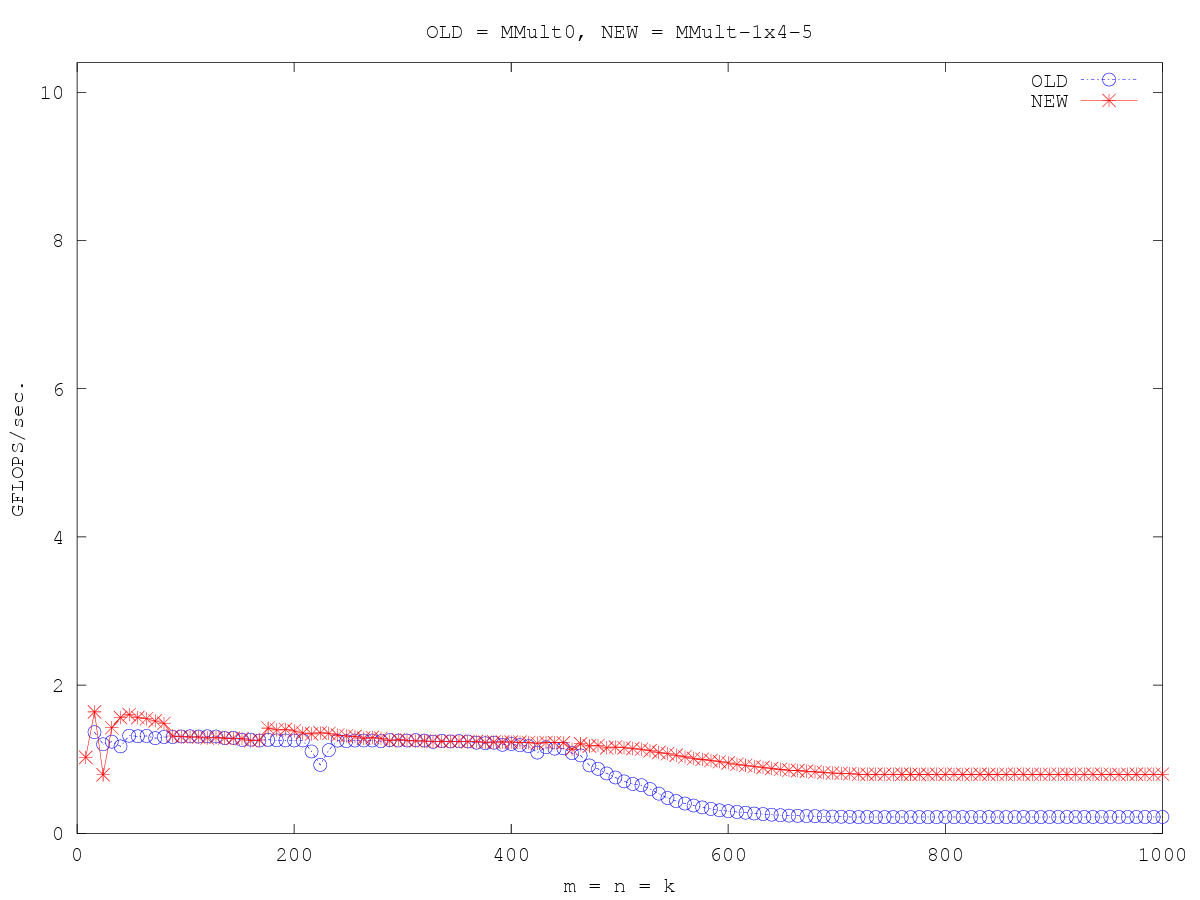
- Optimization_1x4_5 · flame/how-to-optimize-gemm Wiki (github.com)
在这一点上,我们开始看到一些性能改进:
Optimization_1x4_3
1 | |
Optimization_1x4_4
1 | |
Optimization_1x4_5
在这个版本,我们开始看到性能上的好处。原因是四个循环已经融合,因此四个内部乘积运算现在正在同时进行。这有以下好处:
- 索引p只需要每8次浮点操作更新一次(4次乘法4次加法)。
- 元素A(0, p)只需要从内存中取出一次,而不是四次。(只有当矩阵不再适合二级缓存时,这才有好处)
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!