Further optimizing
Further optimizing
- 我们将C的元素累加到寄存器中,并使用寄存器存储a的元素
- Optimization_1x4_6 · flame/how-to-optimize-gemm Wiki (github.com)
- 我们使用指针来定位B中的元素
- Optimization_1x4_7 · flame/how-to-optimize-gemm Wiki (github.com)
- 我们将循环展开4次(展开因子的选择相对任意)
- Optimization_1x4_8 · flame/how-to-optimize-gemm Wiki (github.com)
- 我们使用间接寻址来减少需要更新指针的次数
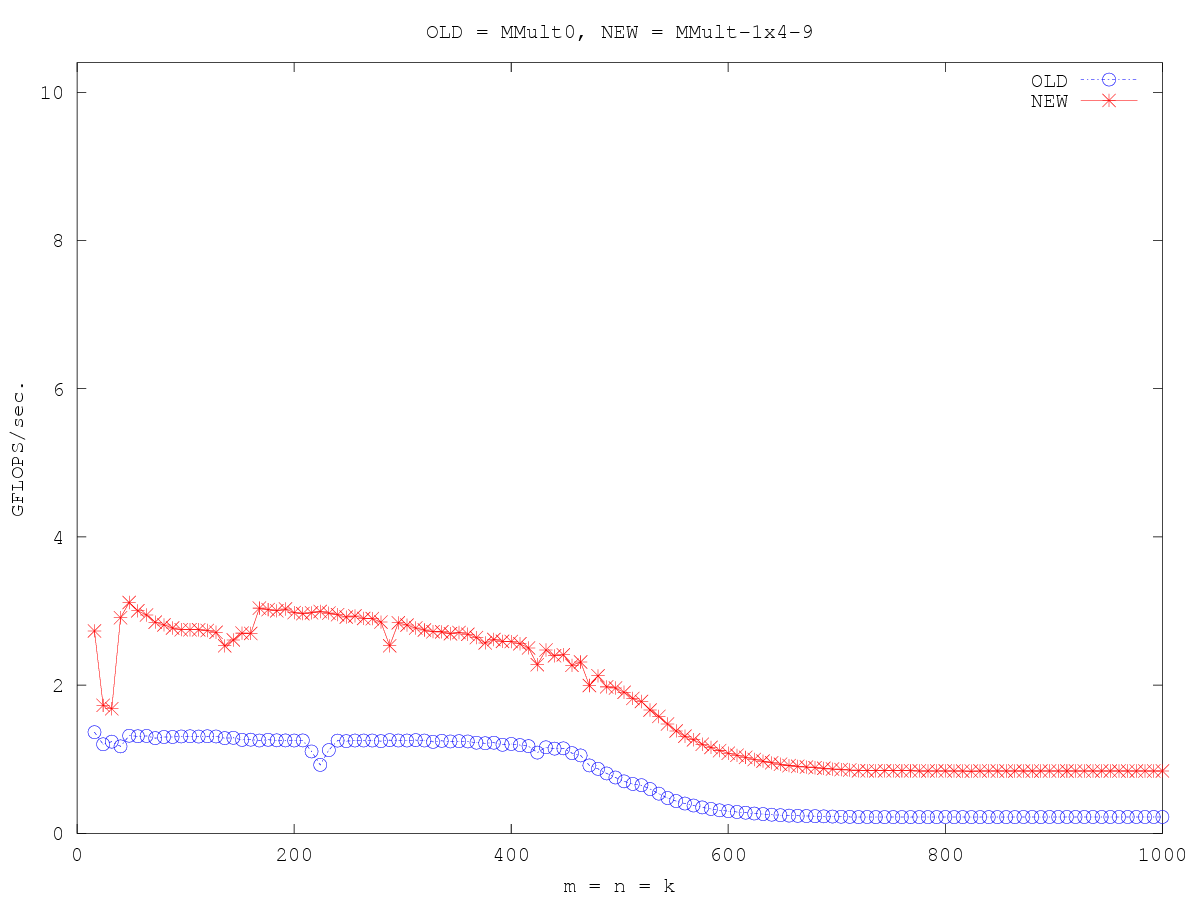
- Optimization_1x4_9 · flame/how-to-optimize-gemm Wiki (github.com)
对于问题大小适合L2缓存(至少部分地)有相当大的改进。不过,还有很大的改进空间。
Optimization_1x4_6
我们在寄存器中对当前1x4行C的更新累积,并将元素A(p, 0)放在寄存器中,以减少缓存(cache)和寄存器(reg)之间的流量(traffic)。
1 | |
Optimization_1x4_7
现在使用bp0_pntr、bp1_pntr、bp2_pntr和bp3_pntr四个指针来访问元素B(p, 0)、B(p, 1)、B(p, 2)、B(p, 3)。这减少了索引开销。
1 | |
Optimization_1x4_8
我们现在展开了4个循环。有趣的是,这会略微降低性能。这可能意味着,通过添加优化,我们混淆了编译器,因此它不能做以前做的优化。
1 | |
Optimization_1x4_9
在这里,*a0p_reg保存元素A(0, p+1)。
我们希望bp0_pntr指向元素B(p,0)。因此,bp0_pntr+1寻址元素B(p+1,0)。有一条特殊的机器指令可以访问bp0_pntr+1处的元素,该指令不需要更新指针。
因此,指向B列中元素的指针只需要在循环的第四次迭代中更新一次。
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!