Repeating the same optimizations
Repeating the same optimizations
- 我们在AddDot4x4子程序中一次计算4个C元素,该子程序一次执行16个乘积:
- Optimization_4x4_3 · flame/how-to-optimize-gemm Wiki (github.com)
- 现在我们内联16个独立的内积,并将循环融合为一个,从而在一个循环中同时计算16个乘积:
- Optimization_4x4_4 · flame/how-to-optimize-gemm Wiki (github.com)
- Optimization_4x4_5 · flame/how-to-optimize-gemm Wiki (github.com)
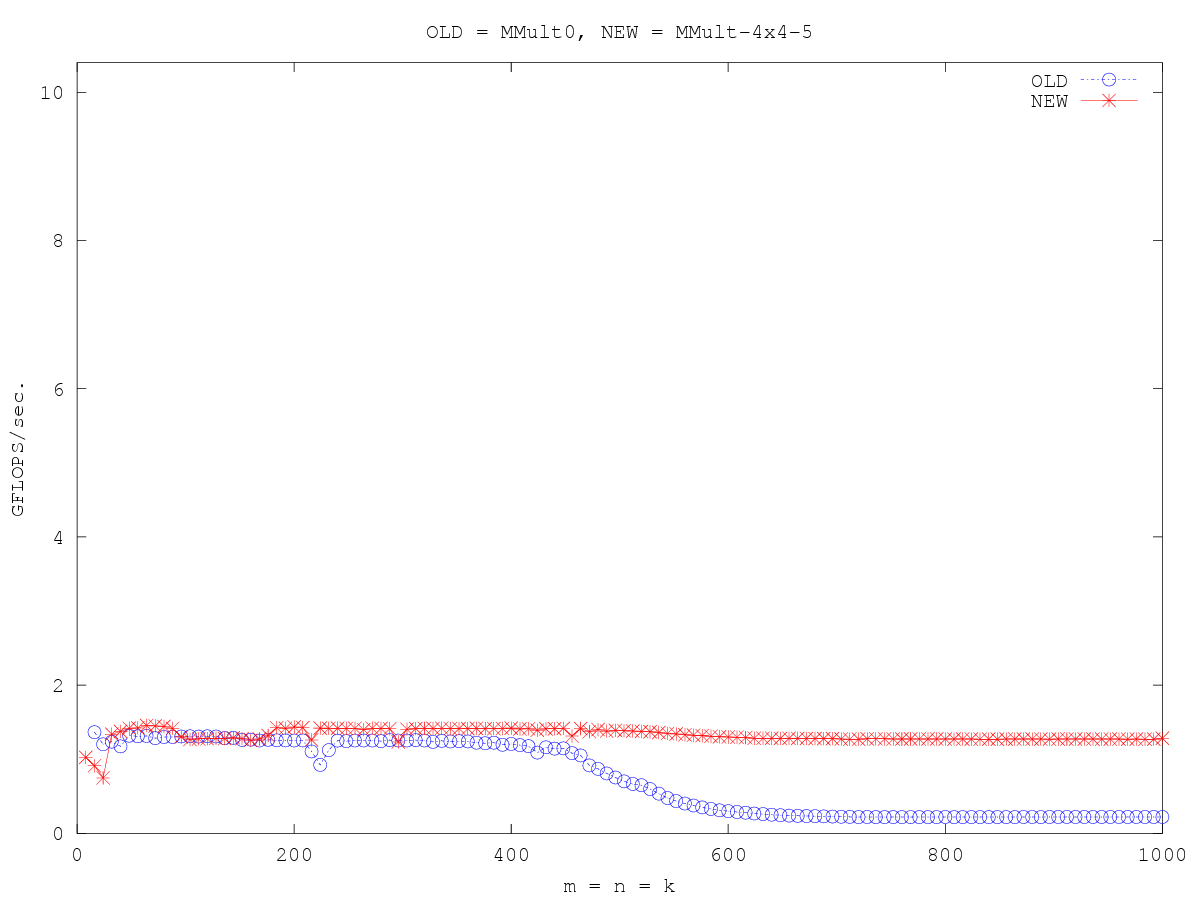
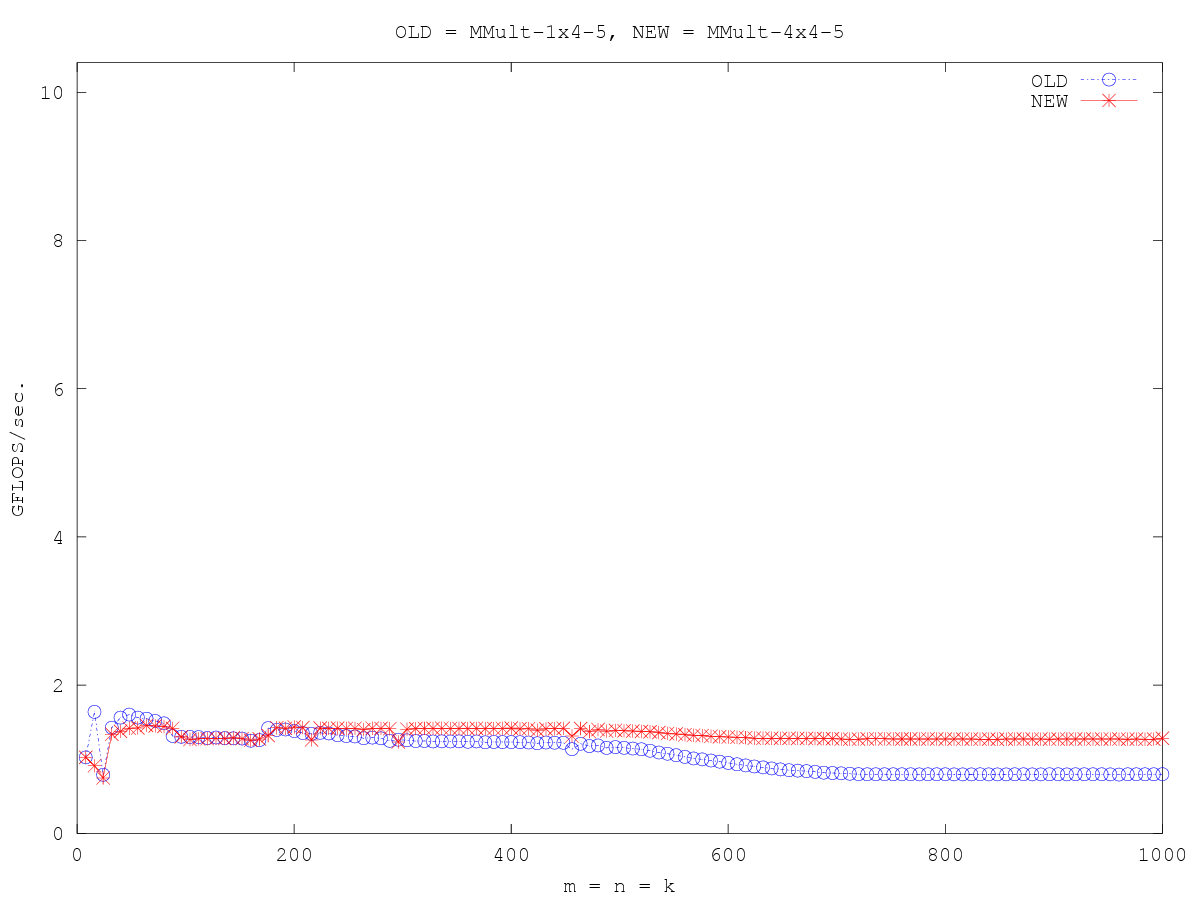
在这一点上,我们再次开始看到一些性能改进:
- 我们将C的元素累加到寄存器中,并使用寄存器存储a的元素
- Optimization_4x4_6 · flame/how-to-optimize-gemm Wiki (github.com)
- 我们使用指针来定位B中的元素
- Optimization_4x4_7 · flame/how-to-optimize-gemm Wiki (github.com)
Optimization_4x4_3
对循环变量i进行展开。由原来AddDot1x4变为AddDot4x4,一次计算16个乘积。
1 | |
Optimization_4x4_4
把AddDot计算kernel合并到AddDot4x4里面。
1 | |
Optimization_4x4_5
合并16个for循环。
现在,当矩阵变大时,我们看到了性能上的好处,因为数据在被放入寄存器后会得到更多的重用。
以前是:1x4_5(一次计算C的4个元素)现在是:4x4_5(一次计算C的16个元素)。
1 | |
Optimization_4x4_6
矩阵C和A采用寄存器来存。
我们为C的4x4块和A的当前4x1列的元素使用(常规)寄存器,这一事实使性能受益。请注意,我们使用的是比实际存在的更多的常规寄存器,所以任何人都可以猜测编译器会用它做什么。
1 | |
Optimization_4x4_7
这里我们改为使用指针来跟踪B的当前4x1块。
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!